



이번주 AI 뉴스 📰
")
"GPT-5가 더 멍청해진 이유"…샘 올트먼, 라우터 오류 인정
성능 저하 원인 : GPT-5 성능이 더 나빠졌다는 불만에 대해, 출시 초기 '자동 전환 라우터'의 오작동 때문이라고 해명함.
사용자 요구 수용 : 유료 구독자를 위해 이전 모델인 GPT-4o를 다시 사용할 수 있게 하는 방안과 사용량 2배 확대를 검토 중임.
발표 실수 인정 : 발표 당시 논란이 된 부정확한 차트에 대해 '엄청난 실수'였다고 인정하며 불안정한 출시에 대해 사과함.

앤트로픽 ‘Claude', 과거 대화 기억 기능 출시…ChatGPT와 차이점은?
기억 기능 출시 : 앤트로픽이 AI 챗봇 '클로드'에 사용자가 요청 시 과거 대화를 검색하고 요약해주는 기능을 추가함.
챗GPT와 차이점 : 자동으로 정보를 축적하는 챗GPT와 달리, 사용자가 요청할 때만 작동하는 '선택적 기억' 방식임.
AI 경쟁 심화 : OpenAI와의 경쟁 속에서 사용자 이탈을 막고 서비스 충성도를 높이기 위한 전략으로 분석됨.

약물 데이터 없이 단백질 구조만으로…카이스트, 항암 신약 설계 AI 개발
데이터 없는 설계 : 카이스트 연구팀이 기존 약물 정보 없이 단백질 구조만으로 최적의 신약 후보 물질을 설계하는 AI를 개발함.
동시 설계 방식 : 분자 생성과 결합 예측을 동시에 수행해 여러 조건을 한 번에 최적화함으로써 설계 성공률을 크게 높임.
신약 개발 가속 : 실제 암 표적 단백질에 작용하는 분자 생성에 성공해 신약 개발의 패러다임을 바꿀 것으로 기대됨.
이번주 AI 논문 📝
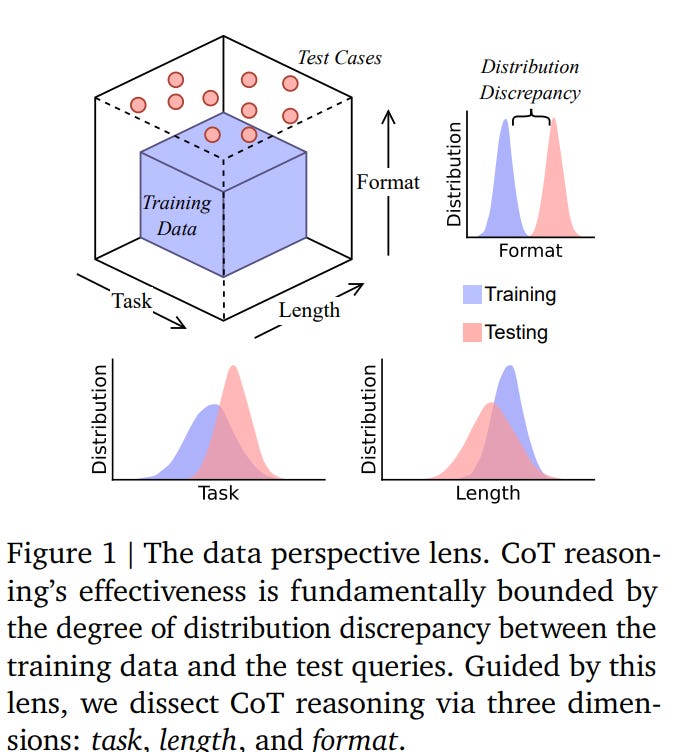
의문의 시작 : LLM이 단계별로 생각하는 과정(CoT)을 보여주는 것이 진짜 추론인지, 아니면 단순히 배운 것을 흉내 내는 것인지에 대한 의문을 제기함.
특별한 실험 : 연구진은 LLM에게 특정 유형의 문제만 가르친 뒤, 배운 적 없는 새로운 유형의 문제를 줘서 진짜 추론 능력이 있는지 시험함.
결론은 '흉내 내기' : LLM은 배운 범위를 벗어나자 추론 능력이 바로 무너졌고, 이는 진짜 생각이 아닌 훈련 데이터의 풀이 과정을 흉내 내는 것임을 보여줌.
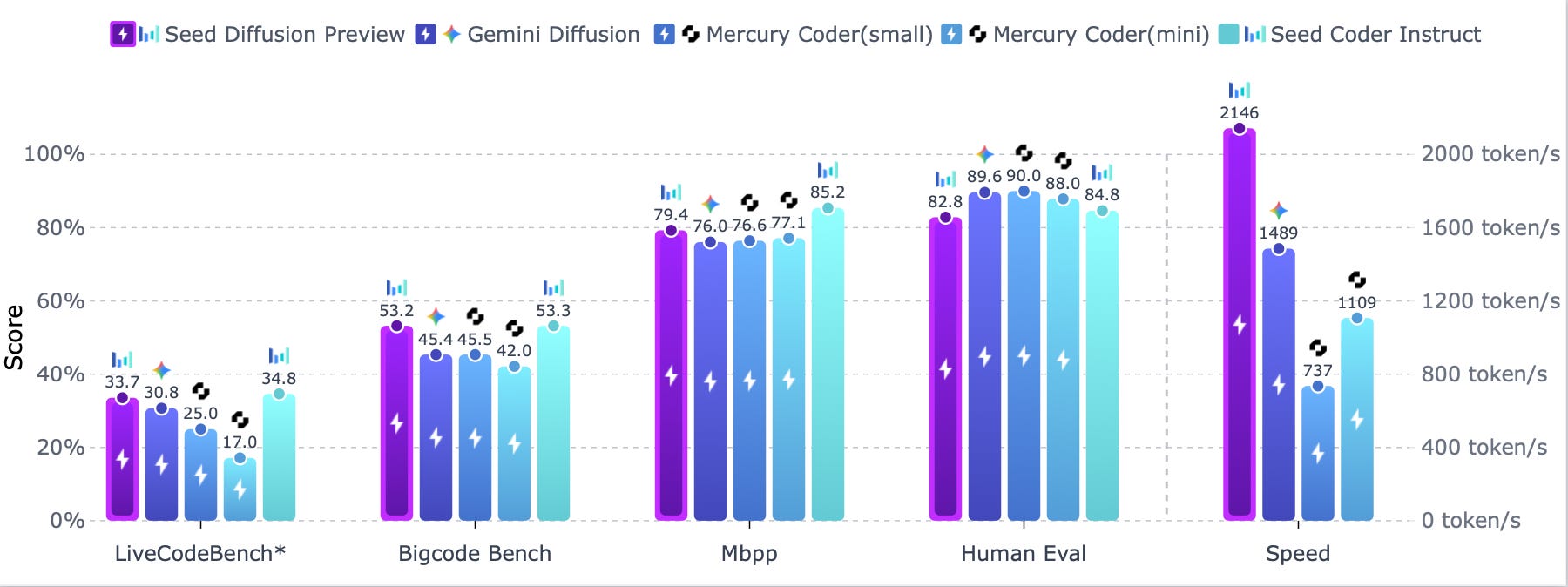
시드 디퓨전(Seed Diffusion): 초고속 추론의 대규모 확산 언어 모델
병렬 생성 확산 모델 : 이산 상태 확산(discrete-state diffusion) 기술을 기반으로 하는 새로운 대규모 언어 모델 'Seed Diffusion'을 공개함. 순차적 생성이 아닌 병렬 생성을 통해 추론 속도를 획기적으로 높임.
획기적인 추론 속도 : H20 GPU 환경에서 초당 2,146 토큰의 추론 속도를 달성했으며, 이는 동시대의 머큐리(Mercury)나 제미나이 디퓨전(Gemini Diffusion) 모델보다 훨씬 빠른 속도임.
속도-품질 신기록 : 주요 코드 평가 벤치마크에서 경쟁력 있는 성능을 유지하면서, 코드 모델의 '속도-품질' 효율 곡선(Pareto frontier)에서 새로운 최고 수준(SOTA)을 달성함.
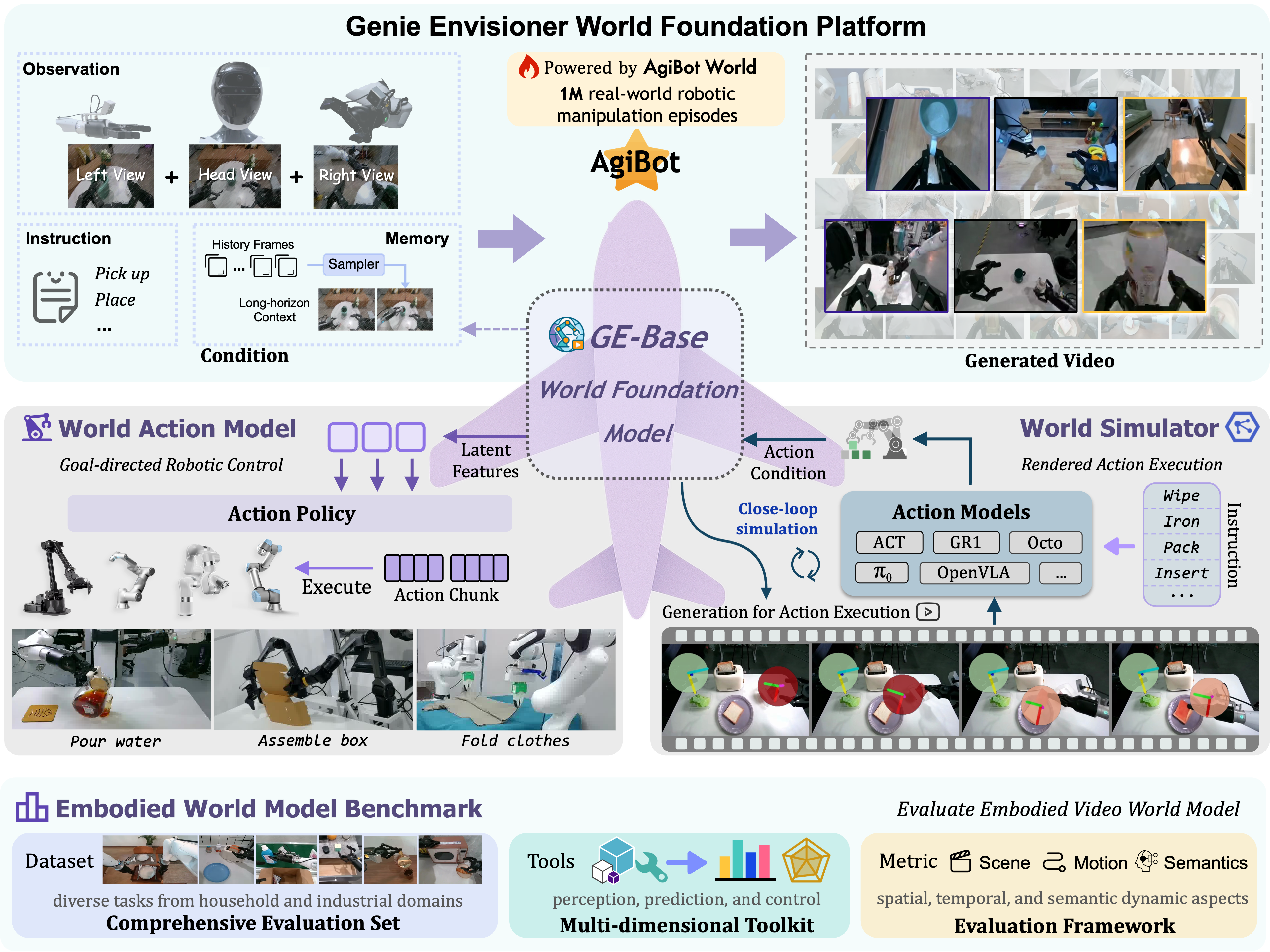
지니 인비저너(GE): 로봇 조작을 위한 통합 월드 파운데이션 플랫폼
로봇 조작 통합 체계 : 로봇 조작에 필요한 정책 학습, 평가, 시뮬레이션을 단일 비디오 생성 프레임워크 안에 통합한 '지니 인비저너(GE)' 플랫폼을 제안함.
세 가지 핵심 구성요소 : 플랫폼은 영상 생성 모델(GE-Base)을 기반으로, 잠재 공간을 실제 행동으로 변환하는 정책(GE-Act)과 행동에 따른 결과를 예측하는 신경 시뮬레이터(GE-Sim)로 구성됨.
범용 로봇 지능 토대 : 이 구성요소들은 지시 기반의 범용 로봇 지능을 위한 실용적 토대를 마련함. 모든 코드, 모델, 벤치마크는 공개될 예정임.
이번주 AI 프로덕트 🎁
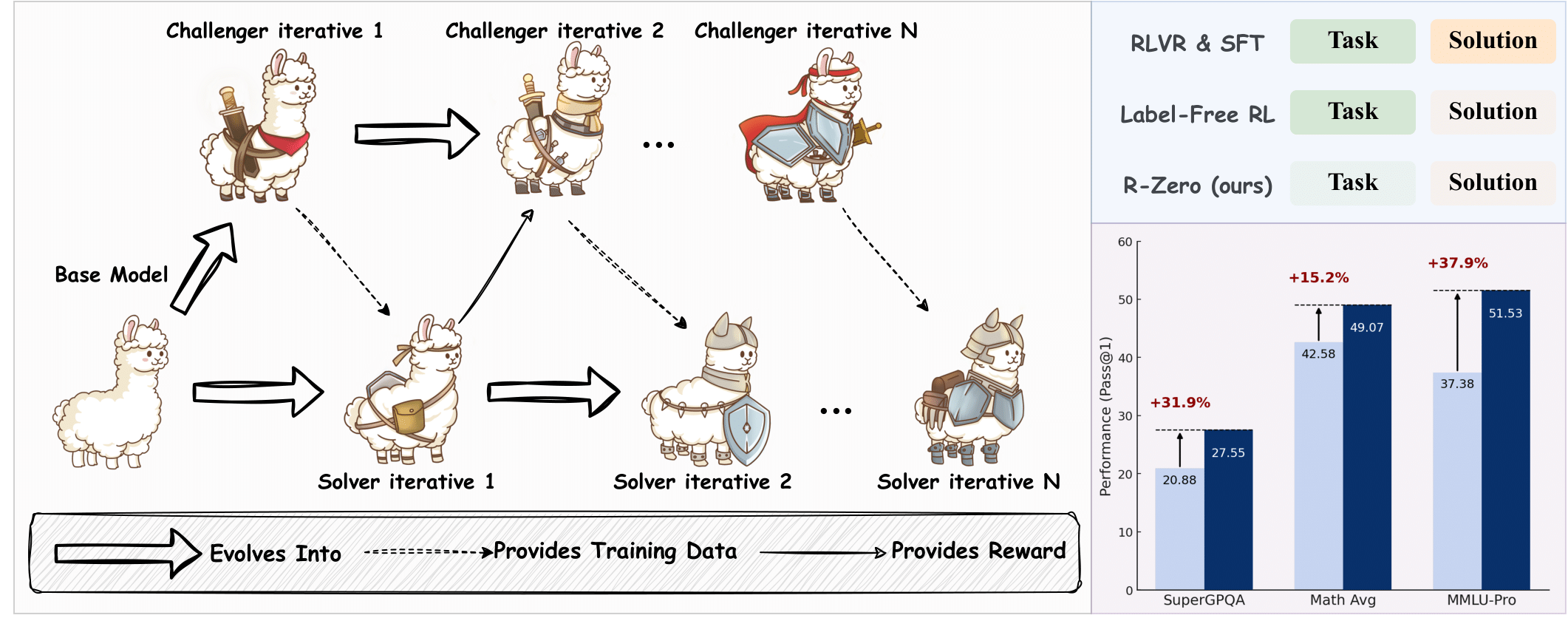
알-제로(R-Zero): 제로 데이터에서 시작하는 자기 진화 추론 LLM
데이터 의존 탈피 : 기존 자기 진화 LLM이 대규모 인간 제작 데이터에 의존하는 한계를 극복하고자, 사전 데이터 없이 스스로 학습 데이터를 생성하는 완전 자율 프레임워크 'R-Zero'를 제안함.
두모델의 상호 진화 : 하나의 기본 모델에서 '도전자(Challenger)'와 '해결사(Solver)'라는 두 독립 모델을 생성함. 도전자는 해결사의 능력에 맞는 문제를 내고, 해결사는 점점 어려워지는 문제를 풀면서 함께 진화함.
추론 능력 대폭 향상 : 이 과정을 통해 외부 데이터 없이도 자체적으로 학습 커리큘럼을 만들어내며, 실제 실험에서 Qwen3-4B와 같은 기본 모델의 수학 및 일반 추론 능력을 큰 폭으로 향상시킴.
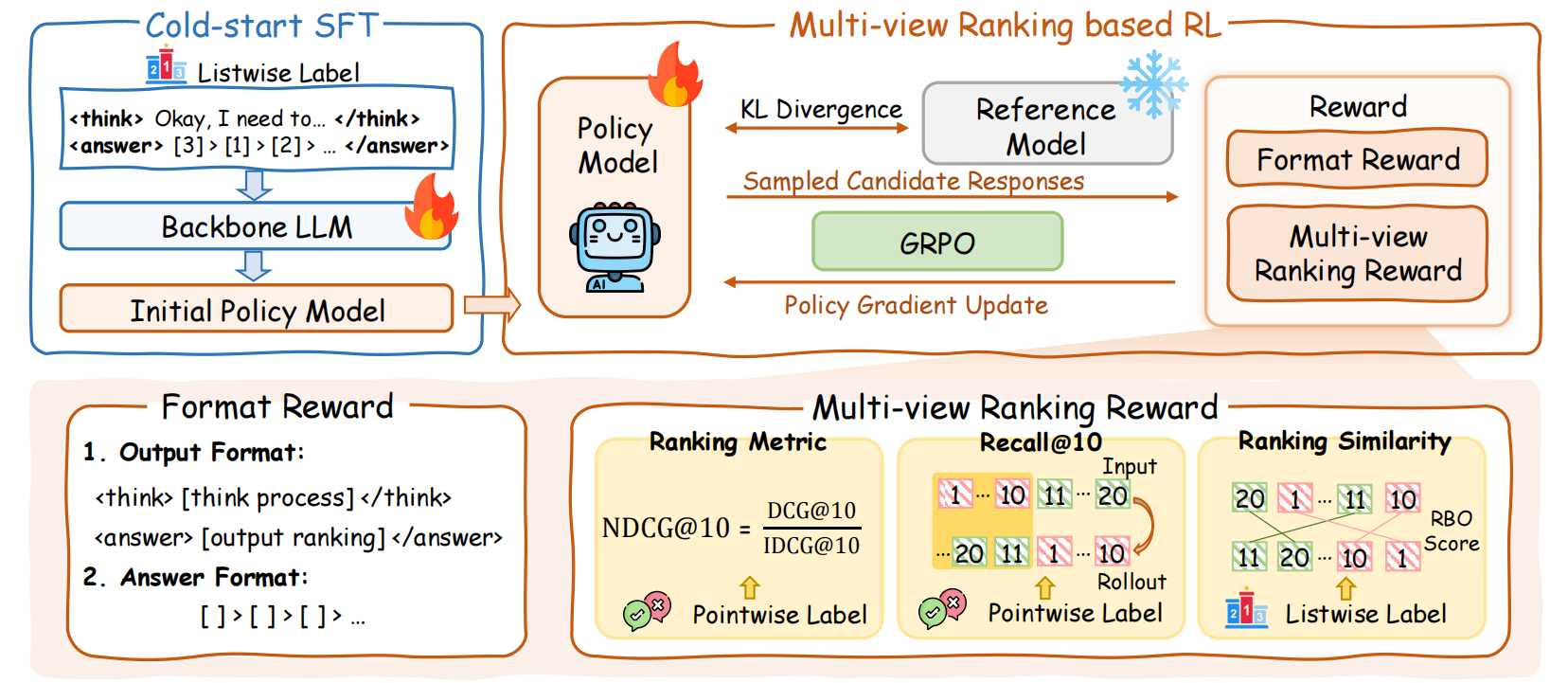
리즌랭크(ReasonRank): 강력한 추론 능력 기반의 구절 랭킹 고도화
추론 데이터 자동 생성 : 기존 구절 랭킹 모델이 복잡한 추론을 요구하는 데이터 부족으로 성능 한계를 보이는 문제를 해결하고자, 추론 중심의 훈련 데이터를 자동으로 합성하는 프레임워크를 개발함.
2단계 추론 능력 학습 : 모델에 강력한 추론 능력을 부여하기 위해, 추론 패턴을 학습하는 지도 미세조정(SFT) 단계와 랭킹 능력을 강화하는 강화학습(RL) 단계를 포함하는 2단계 훈련 방식을 제안함.
SOTA 및 코드 공개 : 실험 결과, ReasonRank는 기존 모델들을 큰 폭으로 능가했으며 BRIGHT 리더보드에서 최고 수준(SOTA)의 성능을 달성함. 관련 코드는 모두 공개됨.








Share this post