



이번주 AI 뉴스 📰

OpenAI, GPT-5 출시 임박...이번 주 목요일 유력
출시 임박 암시 : 샘 알트먼 CEO 등 OpenAI 경영진이 소셜 미디어를 통해 GPT-5 출시가 임박했음을 시사했음.
유력 출시일 : 업계에서 예상된 8월 초 출시설에 따라, 관행상 이번 주 목요일(7일) 공개 가능성이 높게 점쳐짐.
사전 준비 : 파트너사인 마이크로소프트 역시 GPT-5 탑재를 위한 새로운 코파일럿 모드를 출시하며 대비하는 움직임을 보임.

Anthropic, '서비스 약관 위반'하며 OpenAI의 클로드 접근 차단
접근 차단 : Anthropic이 OpenAI의 자사 AI 모델 '클로드'에 대한 API 접근을 차단했음.
위반 사유 : OpenAI가 GPT-5 출시를 앞두고 Claude를 활용해 자체 모델과 비교한 것을 서비스 약관 위반으로 판단함.
양측 입장 : OpenAI는 '업계 표준'이라며 유감을 표했고, Anthropic은 안전성 평가 목적의 접근은 계속 허용할 방침임.

AI 검색 Perplexity, '무단 수집' 논란...차단도 무시
무단 수집 의혹 : Cloudfare가 "Perplexity가 웹사이트의 AI 스크래핑 차단 설정을 무시하고 데이터를 수집했다"고 폭로했음.
신원 위장 수법 : 봇의 신원을 숨기기 위해 일반 브라우저인 것처럼 사용자 에이전트(user agent)를 변경하는 방식을 사용한 것으로 드러났음.
엇갈린 공방 : 퍼플렉시티는 '영업 홍보'라며 혐의를 부인했고, 클라우드플레어는 해당 봇에 대한 차단 조치에 나섰음.
이번주 AI 논문 📝
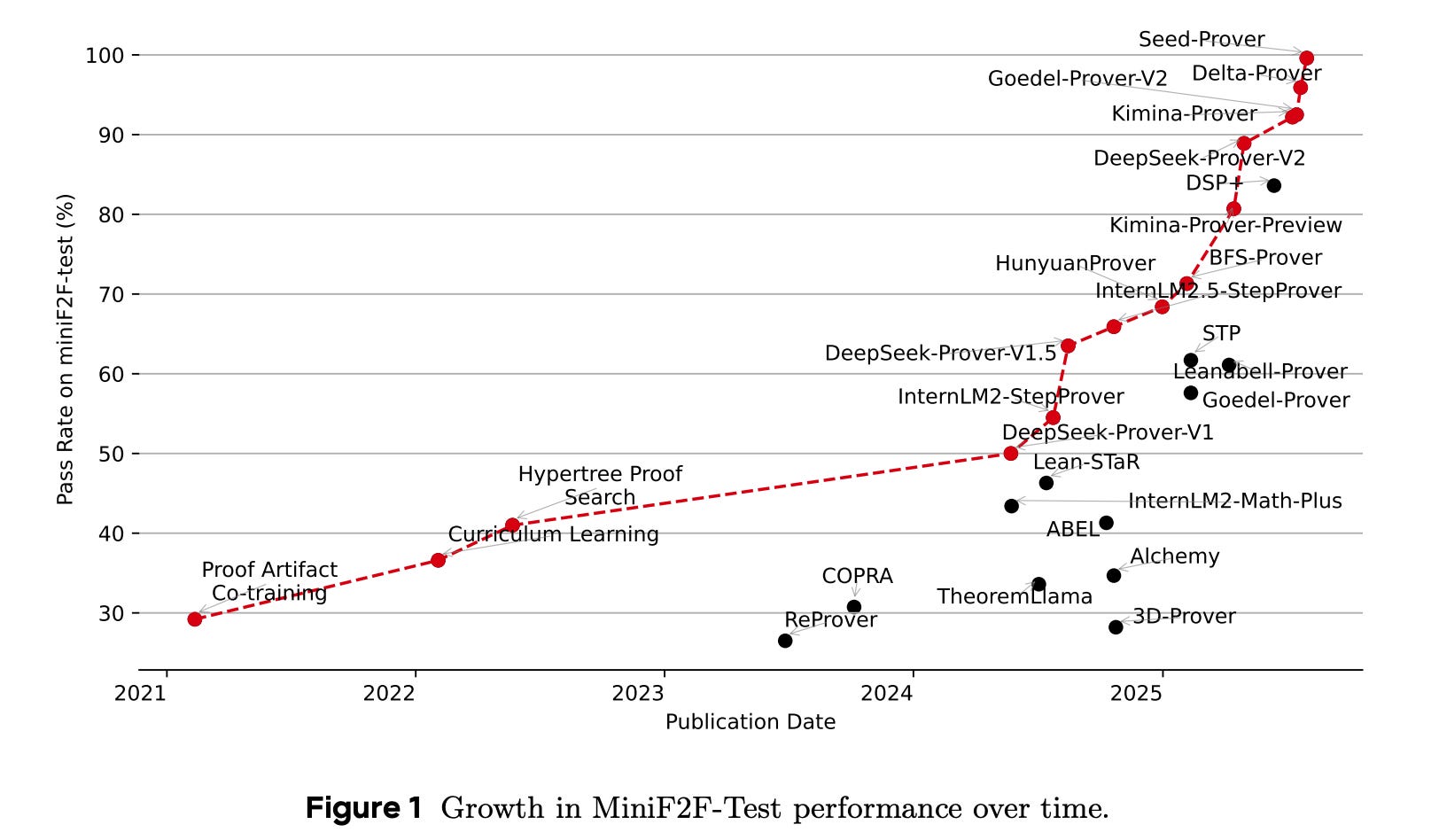
Seed-Prover : 자동 정리 증명을 위한 깊고 넓은 추론
정형 검증 활용 모델 : 자연어만으로는 명확한 감독 신호가 없어 LLM이 정리 증명에 어려움을 겪는 문제를 해결하고자, Lean과 같은 정형 검증 피드백을 활용하는 보조정리 스타일의 추론 모델 'Seed-Prover'를 제안함.
벤치마크 성능 압도 : 깊고 넓은 추론이 가능한 3가지 추론 전략을 통해 과거 IMO 문제의 78.1%를 증명하고 MiniF2F, PutnamBench 등 주요 벤치마크에서 기존 최고 성능을 큰 폭으로 능가함.
IMO 2025 성과 : 자체 개발한 기하학 추론 엔진 'Seed-Geometry'와 함께 2025년 국제수학올림피아드(IMO)에 참가하여, 6문제 중 5문제를 완전히 증명하는 데 성공함.

뱅(BANG): 생성형 폭발 동역학을 통한 3D 에셋 분할
3D 객체 분해 자동화 : 기존 3D 디자인 툴이 3D 객체를 부품 단위로 분해하는 데 많은 수작업을 요구하는 문제를 해결하고자, '생성형 폭발 동역학'이라는 새로운 접근법을 제안함.
생성형 폭발 동역학 : 사전 훈련된 확산 모델을 기반으로, 부품들이 기하학적/의미적 일관성을 유지하며 부드럽게 분리되는 동적 시퀀스를 생성함. 사용자는 바운딩 박스 등 공간적 프롬프트로 분해 과정을 제어할 수 있음.
제조 및 3D 프린팅 : 이 기술은 상세한 부품 단위 지오메트리 생성을 가능하게 하며, 특히 조립이 용이하도록 분리된 부품을 만들어 3D 프린팅 및 제조 워크플로우에 유용하게 적용됨.

애니멀클루(AnimalClue): 동물의 흔적으로 종 식별하기
동물 흔적 데이터셋 : 기존 컴퓨터 비전 연구가 동물의 직접적인 모습에 집중한 반면, 발자국이나 배설물 등 간접적인 흔적을 통한 종 식별 연구는 부족했음. 이 격차를 해소하고자 최초의 대규모 동물 흔적 데이터셋 'AnimalClue'를 구축함.
데이터셋의 구성 : 데이터셋은 발자국, 배설물, 알, 뼈, 깃털 등 5가지 단서 카테고리에 걸쳐 968종의 159,605개 바운딩 박스로 구성됨. 종 라벨 외에 세분화된 특성 정보까지 포함함.
새로운 과제와 기여 : 이 데이터셋은 동물의 외형이 아닌 미묘하고 세밀한 시각적 특징을 인식해야 하므로 기존 모델에 새로운 도전 과제를 제시함. 데이터셋과 코드는 모두 공개됨.
이번주 AI 프로덕트 🎁
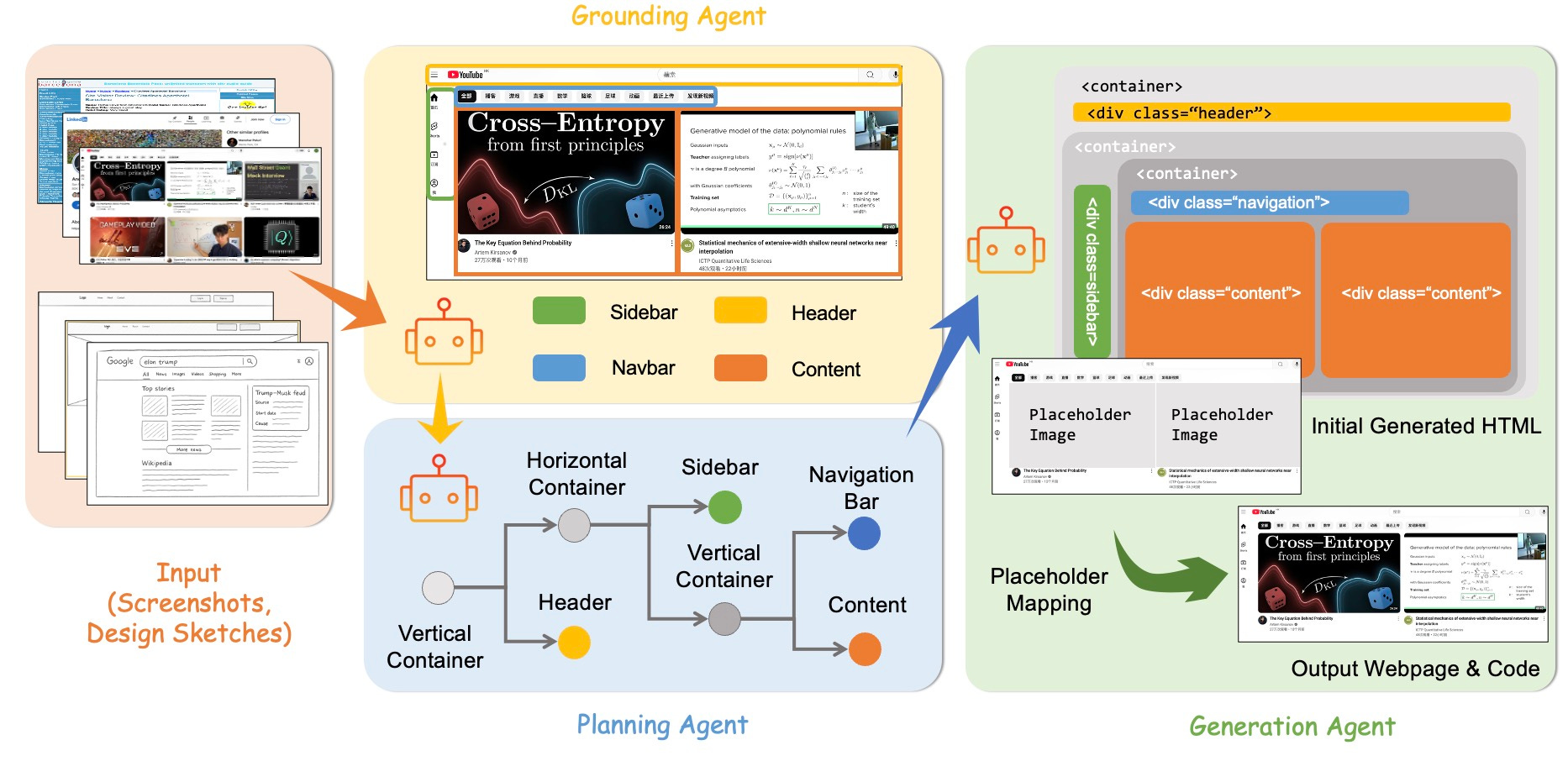
스크린코더: 모듈형 멀티모달 에이전트를 통한 프론트엔드 자동화 툴
모듈형 에이전트 접근 : 기존 LLM이 시각적 UI 디자인을 코드로 변환하는 데 겪는 한계를 극복하고자, '인식-계획-생성'의 3단계로 작업을 분리한 모듈형 멀티 에이전트 프레임워크를 제안함.
데이터 생성 및 학습 : 이 프레임워크를 확장하여 대규모 이미지-코드 쌍 데이터를 자동으로 생성하는 데이터 엔진을 구축했으며, 이 합성 데이터를 활용해 오픈소스 VLM을 미세조정하여 성능을 향상시킴.
SOTA 및 코드 공개 : 실험 결과, 제안된 접근법은 레이아웃 정확도, 구조적 일관성, 코드 정확성에서 기존 최고 수준(SOTA)의 성능을 달성했으며, 코드는 공개적으로 이용 가능함.

엑스-옴니(X-Omni): 강화학습을 통한 자기회귀 이미지 생성 모델
버려진 방식의 부활 : 기존의 자기회귀(autoregressive) 이미지 생성 방식은 품질 저하 문제로 외면받아 왔음. 본 연구는 강화학습(RL)을 통해 이 방식의 단점을 효과적으로 완화하고 품질을 크게 향상시킬 수 있음을 증명함.
강화학습 기반 구조 : 이를 위해 이미지 토크나이저, 언어와 이미지를 위한 통합 자기회귀 모델, 오프라인 확산 디코더로 구성된 'X-Omni' 프레임워크를 제안함. 강화학습이 생성 과정의 오류를 바로잡는 핵심 역할을 수행함.
SOTA 및 지시 이행 : 7B 언어 모델 기반의 X-Omni는 이미지 생성 과제에서 기존 최고 수준(SOTA)의 성능을 달성했으며, 특히 높은 미적 품질과 복잡한 지시사항 및 긴 텍스트 렌더링 능력에서 강점을 보임.








Share this post