



이번주 AI 뉴스 📰

소송 때문에 밝혀진 OpenAI의 비밀 AI 기기 계획?
치밀한 시장 조사 : 상표권 소송 과정에서 OpenAI와 io가 AI 기기 개발을 위해 30개 이상의 헤드폰을 구매하고 경쟁사 기술까지 직접 살펴본 사실이 드러남.
반전의 프로토타입 : 하지만 io의 하드웨어 책임자는 법정 진술에서 첫 프로토타입은 인이어(in-ear)나 웨어러블 기기가 아니라고 밝혀 반전을 줌.
베일 속의 첫 제품 : 현재로선 주머니에 넣거나 책상에 두는 형태 등 다양한 기기를 탐색 중이며, 최종 제품 출시는 1년 이상 남은 것으로 보임.

AI 검색 스타트업 퍼플렉시티, 메타·애플 인수설 부상
잇따른 인수 논의 : AI 검색 엔진 스타트업 퍼플렉시티가 메타와 인수 논의를 진행했으며, 애플 또한 내부적으로 인수를 검토한 것으로 알려짐.
빅테크의 위기감 : 이는 구글, OpenAI 등 경쟁사에 비해 AI 기술이 뒤처졌다고 평가받는 두 기업이 유망한 기술과 인재를 확보하려는 시도로 풀이됨.
애플의 대안 찾기 : 특히 애플은 구글과의 검색 엔진 계약이 법적 위기에 처하면서, 퍼플렉시티가 사파리의 유력한 대체재로 떠오르고 있음.

AI 이미지 강자 Midjourney, 영상 모델 ‘V1’ 공개
영상 시장에 참전 : AI 이미지 생성으로 유명한 미드저니가 첫 AI 영상 생성 모델 'V1'을 출시함. 이미지를 올리면 5초짜리 영상으로 만들어주는 방식임.
독특한 최종 목표 : 단순 상업 영상이 아닌, 특유의 몽환적 스타일을 내세움. 최종 목표는 '실시간 가상세계 시뮬레이션'을 만드는 것이라고 밝힘.
비싼 가격과 소송 : 영상 생성 비용은 이미지보다 8배 비싸게 책정됨. 한편, 디즈니 등으로부터 저작권 소송을 당한 직후라 논란도 계속될 전망임.
이번주 AI 논문 📝

Vision-Guided Chunking: 시각 정보로 RAG 성능을 높이는 새로운 청킹 기법
기존 RAG 청킹의 한계: 기존 RAG 시스템은 텍스트 기반으로 문서를 분할(chunking)하여, 여러 페이지에 걸친 표나 그림 같은 복잡한 구조의 의미를 파악하기 어려웠음.
시각 정보를 활용한 해법: 이 문제를 해결하기 위해, 대규모 멀티모달 모델(LMM)을 사용해 PDF 문서의 시각적 구조까지 이해하는 'Vision-Guided Chunking' 방식을 제안함.
RAG 성능 및 정확도 향상: 이 시각 정보 기반 접근법은 문서의 구조와 의미를 더 잘 보존하여, 최종 RAG 시스템의 검색 및 답변 정확도를 크게 향상시키는 결과를 보임.
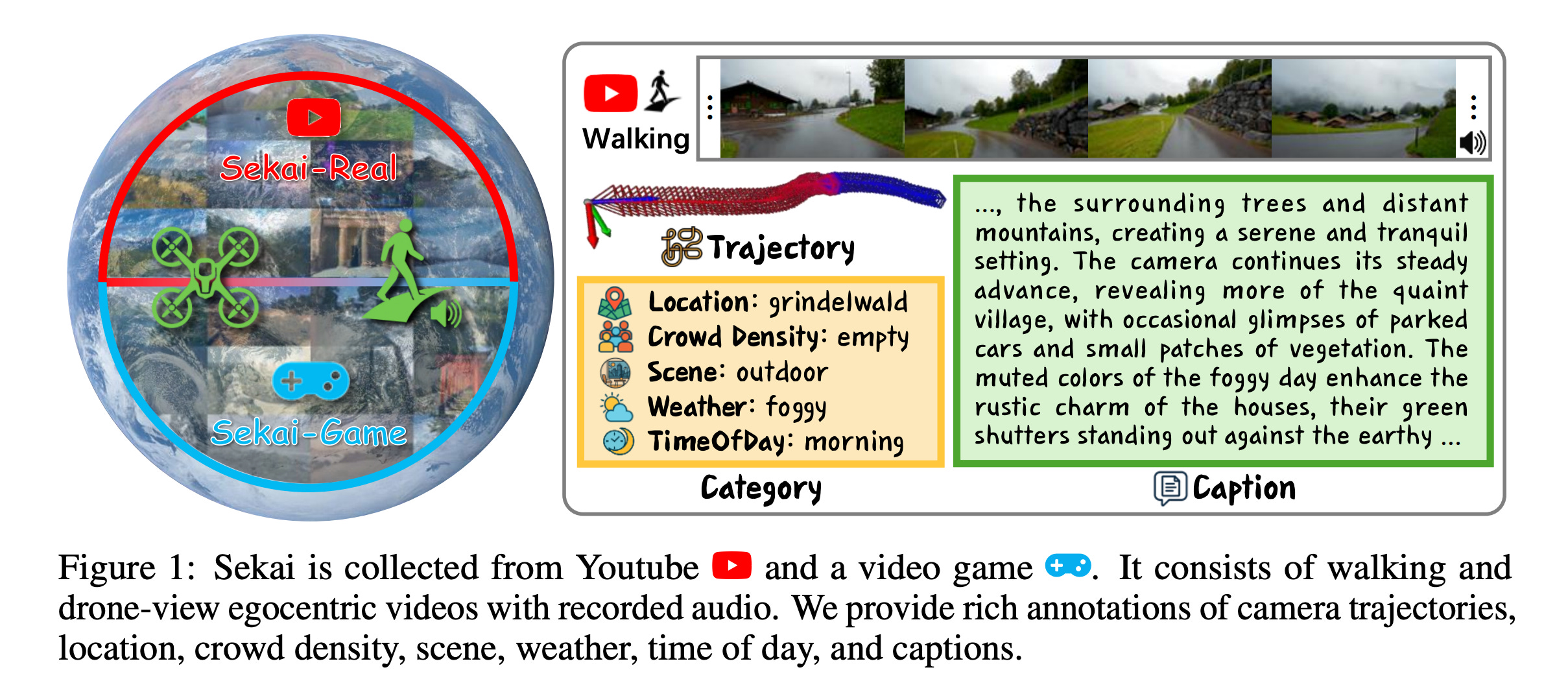
Sekai: '월드 탐험'을 위한 새로운 대규모 영상 데이터셋
새로운 데이터셋 등장: 기존 영상 데이터셋들이 지역, 길이, 주석 부족 등의 한계를 갖는 문제를 해결하기 위해, '월드 탐험(world exploration)' 훈련을 위한 새로운 1인칭 영상 데이터셋 'Sekai'가 공개됨.
방대한 규모와 주석: Sekai 데이터셋은 100개 이상의 국가, 750개 도시에서 수집한 5,000시간 이상의 영상으로 구성됨. 위치, 날씨, 카메라 경로 등 풍부한 주석을 포함하는 것이 특징임.
탐험 모델 YUME 개발: 연구진은 이 데이터셋의 일부를 사용해 'YUME'라는 이름의 상호작용형 월드 탐험(interactive world exploration) 모델을 훈련시켜 데이터셋의 효용성을 입증함.

Drag-and-Drop LLM: 학습 없이 프롬프트만으로 LLM 맞춤화
학습 없는 LLM 맞춤화: 기존 LLM 맞춤화 기술인 PEFT가 모든 작업마다 별도 학습을 요구하는 한계를 극복하기 위해, 'Drag-and-Drop LLM(DnD)'이라는 새로운 방법론이 제안됨.
프롬프트 기반 가중치 생성: 이 기술은 특정 작업에 대한 프롬프트 몇 개만 입력하면, 별도 학습 과정 없이 바로 해당 작업에 최적화된 LoRA 가중치를 직접 생성함.
비용 절감과 성능 향상: 연구 결과, 기존 방식보다 최대 12,000배 낮은 비용으로 더 높은 성능(최대 30% 향상)을 보였고, 처음 보는 데이터에도 뛰어난 일반화 능력을 입증함.
이번주 AI 프로덕트 🎁

Guru: 6개 도메인에 걸친 LLM 추론을 위한 강화학습(RL) 데이터셋
다중 도메인 추론 데이터셋: 수학, 코드 외에 다양한 추론 영역에서 RL 훈련 데이터가 부족한 문제를 해결하기 위해, 6개 도메인을 포괄하는 데이터셋 'Guru'를 구축함.
고성능 추론 모델: 'Guru' 데이터셋으로 훈련된 'Guru-7B'와 'Guru-32B' 모델을 제시함. 이 모델들은 공개된 데이터로 학습한 모델 중 최고 수준의 범용 추론 성능을 보임.
도메인별 RL 효과 분석: 또한, RL의 효과는 도메인에 따라 다르다는 점을 밝혀냄. 사전학습에 없던 생소한 영역은 해당 도메인 데이터로 직접 훈련해야 실질적인 기술 습득이 가능함을 시사함.

통합 멀티모달 생성 모델: 텍스트-이미지 변환, 편집 등 다양한 생성 작업을 하나의 모델로 처리하는 'OmniGen2'를 소개함. 텍스트와 이미지 디코딩 경로를 분리해 성능을 개선한 것이 특징임.
특화된 학습 데이터 및 기법: 모델 훈련을 위해 자체 데이터 구축 파이프라인을 개발하고, 이미지 생성에 특화된 'reflection mechanism'이라는 새로운 기법을 도입함.
우수한 성능과 자체 벤치마크: 작은 크기에도 불구하고 뛰어난 성능을 보이며, 자체 제작한 'OmniContext' 벤치마크에서는 최고 수준의 결과(SOTA)를 달성함.









Share this post