



이번주 AI 뉴스 📰

中 AI 기업, 美 칩 규제 우회를 위한 해외 원정중?
데이터 해외 원정: 미국의 고성능 AI 칩 제재를 피하기 위해, 중국 기업들이 하드드라이브에 데이터를 담아 말레이시아 등 제3국으로 직접 날아가 AI 모델을 훈련시키고 있음.
美 규제 우회 전략: 이는 미국이 중국으로의 AI 칩 판매 및 밀반입 단속을 강화하자, 규제의 허점을 파고들어 등장한 새로운 우회 전략임.
동남아 허브 부상: 이런 수요 덕에 말레이시아 등 동남아 데이터 센터가 급증하고 있으며, 미국 정부도 이 문제를 인지하고 대응책을 고심 중임.

OpenAI, 미 국방부와 2억 달러 규모 AI 계약 체결
미 국방부와 계약: OpenAI가 미 국방부와 2억 달러 규모의 계약을 맺고, 선제적 사이버 방어 등 국가 안보 과제를 해결하기 위한 AI 기술을 제공하기로 했음.
정부 협력 착수: 이번 계약은 OpenAI의 새로운 정부 협력 이니셔티브의 첫 사례이며, 회사는 AI 기술이 무기 개발이나 타인을 해치는 데 사용될 수 없다는 자사 정책을 준수해야 한다고 밝혔음.
정책 선회와 추세: 이는 과거 '군사 및 전쟁' 분야 사용을 금지했던 OpenAI의 정책 선회를 의미하며, 다른 주요 AI 기업들도 국방 분야와 협력을 강화하는 업계 동향을 반영함.

디즈니·유니버설, 'AI 캐릭터 무단 생성' 미드저니 고소
할리우드의 선전포고: 할리우드 거대 기업인 디즈니와 유니버설이 자사의 유명 캐릭터들을 무단으로 복제했다며 AI 이미지 생성 서비스 '미드저니'를 상대로 저작권 침해 소송을 제기했음.
무단 복제 및 도용: 이들은 미드저니가 다스베이더, 슈렉 등 자사 캐릭터 이미지를 무단 생성하고 마케팅에 활용했으며, 시정 요구도 무시했다고 주장함.
AI 업계와의 전쟁: 이번 소송은 할리우드와 생성형 AI 업계 간의 첫 주요 법적 다툼으로, 곧 출시될 미드저니의 영상 생성 기능까지 문제 삼으며 향후 귀추가 주목됨.
이번주 AI 논문 📝

인간 같은 개념 형성: 다중모드(multimodal) 대형 언어 모델(LLM)이 수많은 객체 데이터를 학습한 결과, 인간과 매우 유사한 방식으로 사물의 개념과 관계를 표현하는 능력을 갖게 되었음을 발견함.
뇌 활동과 유사성: 특히 AI가 만든 객체 개념 지도는 특정 사물을 인식할 때 활성화되는 인간 뇌의 특정 영역 활동 패턴과 높은 정렬성을 보였음.
인간적 AI의 가능성: 이는 AI가 단순 데이터 처리를 넘어 인간과 근본적으로 유사한 개념적 지식을 형성하고 있음을 시사하며, 더 인간적인 인공 인지 시스템 개발의 가능성을 열어줌.
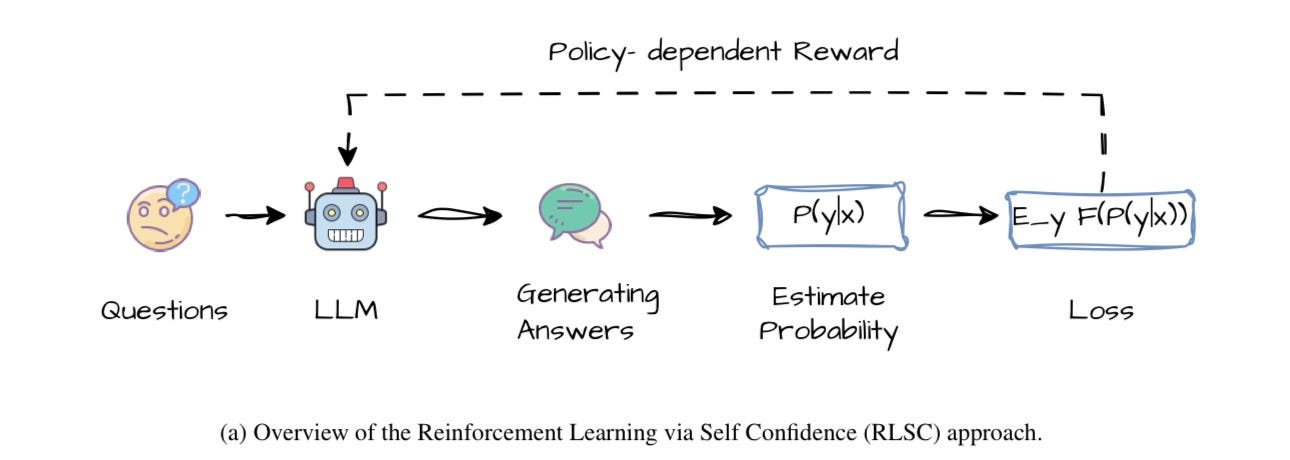
자신감을 보상으로: 기존 AI 모델 미세조정은 막대한 비용이 드는 인간의 피드백을 필요로 했으나, 이 연구는 AI가 스스로 내놓은 답에 대한 '자신감'을 보상 신호로 활용하는 새로운 강화학습(RLSC) 기법을 제안함.
저비용 고효율 학습: 이 방식은 별도의 정답 데이터나 보상 모델 없이, 극소량의 샘플과 짧은 학습만으로 미세조정을 가능하게 하여 비용과 시간을 획기적으로 줄였음.
수학 능력 대폭 향상: 수학 특화 모델에 이 기법을 적용한 결과, 여러 고난도 수학 벤치마크에서 정확도가 최대 21.7%까지 향상되어, 단순하면서도 확장성 높은 방법론의 가능성을 입증함.

AI의 지정학적 편향: 최신 AI 언어 모델(LLM)이 특정 역사적 사건을 해석할 때, 미국, 중국 등 특정 국가의 관점에 치우치는 상당한 지정학적 편향을 가지고 있음을 확인함.
단순 교정의 한계: '편향되지 않게 답하라'와 같은 단순한 지시어(프롬프트)는 이러한 뿌리 깊은 국가적 서사 편향을 줄이는 데 매우 제한적인 효과만 보였음.
정보 출처의 영향: 또한 AI는 정보 출처로 명시된 국가에 따라 편향성이 증폭되기도 하는 등 민감하게 반응했으며, 연구진은 향후 관련 연구를 위한 데이터셋과 분석 틀을 함께 제공함.
이번주 AI 프로덕트 🎁
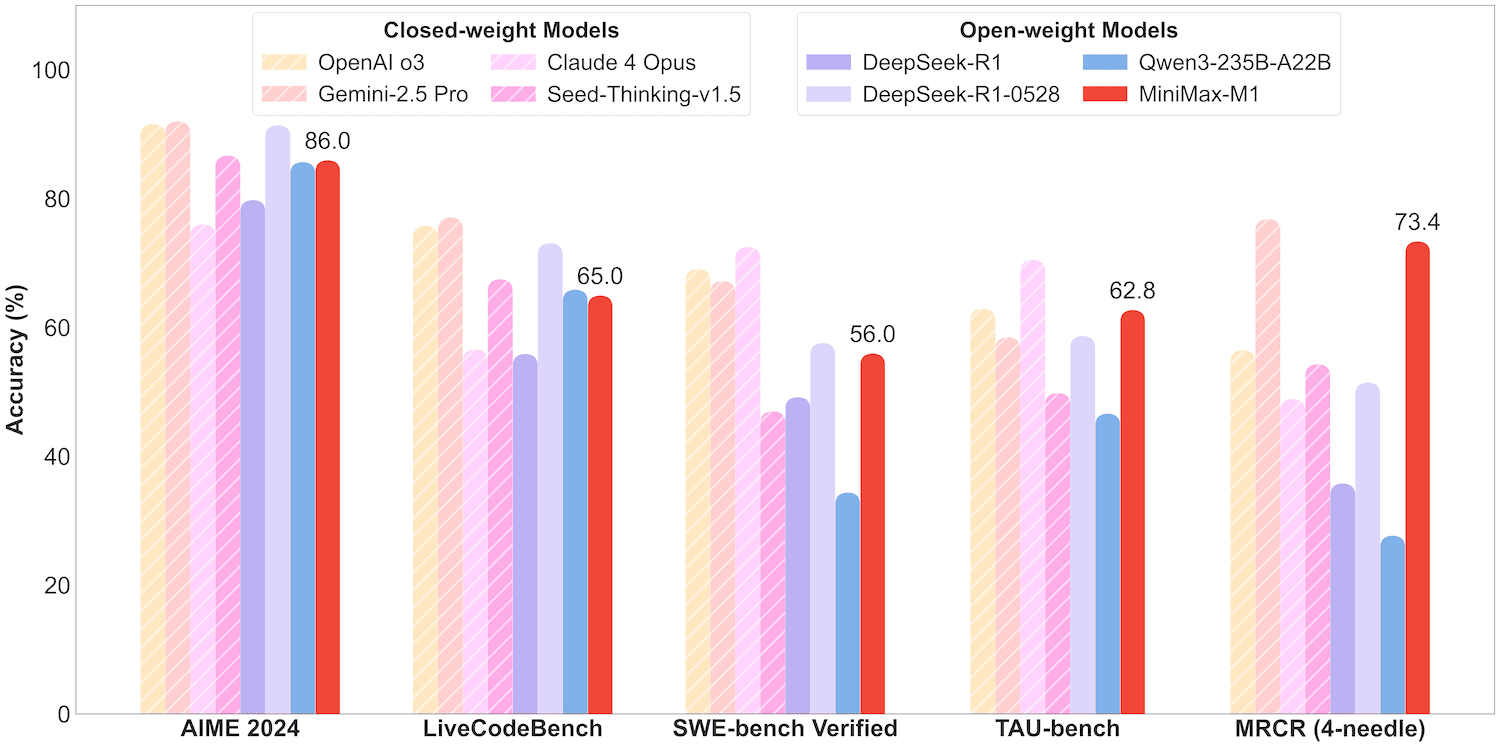
MiniMax-M1: 번개 어텐션 기반의 고효율 장문 추론 모델
'번개 어텐션' 모델: 하이브리드 전문가 혼합(MoE) 구조에 '번개 어텐션' 기술을 결합한 새로운 오픈소스 모델 '미니맥스-M1'이 공개됨. 이 모델은 100만 토큰의 방대한 컨텍스트를 지원함.
초고속 강화학습: 'CISPO'라는 새로운 강화학습 알고리즘을 도입하여 훈련 효율을 극대화했으며, 512개의 GPU로 3주 만에 훈련을 완료하는 등 비용 효율성을 입증함.
긴 컨텍스트에 강점: 이 모델은 특히 긴 컨텍스트 처리, 소프트웨어 엔지니어링, 도구 활용 분야에서 기존 강력한 모델들과 대등하거나 우수한 성능을 보이며 공개적으로 출시됨.

CoRT: 코드 통합 추론을 위한 효율적인 후처리 훈련 프레임워크
CoRT 프레임워크: 대형 추론 모델(LRM)이 복잡한 수학 연산에 외부 코드 도구를 비효율적으로 사용하는 문제를 해결하기 위해, 'CoRT'라는 새로운 후처리(post-training) 훈련 프레임워크를 개발함.
힌트 엔지니어링: 이 프레임워크는 '힌트 엔지니어링' 기법을 통해 모델과 코드 도구 간의 상호작용을 최적화하는 학습 데이터를 자동으로 생성하여 데이터 부족 문제를 해결함.
정확도·효율성 향상: CoRT로 훈련된 모델은 여러 수학 추론 데이터셋에서 정확도가 최대 8% 향상되었고, 토큰 사용량은 최대 50% 감소하여 정확성과 효율성을 모두 크게 개선했음.







{kind=link}
Share this post