



이번주 AI 뉴스 📰

美 공대 졸업생, 미술 전공생 보다 실업률 두 배 높아
공대생 실업률: 미국 컴퓨터 공학 졸업생 실업률이 7.5%로 미술사 전공자(3%)의 두 배 넘는 것으로 나타남.
의외의 결과: 뉴욕 연은 보고서에 따르면, STEM 전공 취업이 잘될 거란 예상과 달리 인문학 전공자들이 더 나은 고용 성과를 보임.
인재상 변화: AI 시대에 창의적 사고와 소프트 스킬 수요가 늘면서, 블랙록 같은 기업들은 인문학 전공자 채용에 관심을 보이기 시작했음.

Builder.ai, AI 스타트업 사기극 드러나며 붕괴
AI 실체 의혹: 15억 달러 규모의 'AI' 스타트업 Builder.ai가 실제로는 AI가 아닌 인도 개발자들이 봇인 척 코딩을 해왔다는 사실이 폭로됨.
파산 보호 신청: 핵심 대출 기관이 3,700만 달러를 인출하면서 자금난에 빠졌고, 영국, 미국 등 5개국에서 파산 보호 신청하고 대규모 해고를 단행함.
업계에 경종: 이 사태는 과장된 홍보와 부족한 재정 관리로 급성장한 AI 스타트업들의 불안정성을 보여주며, 투명성과 윤리적 마케팅에 대한 의문을 제기함.

AI 학습 협약: 뉴욕타임스가 아마존에 자사 편집 콘텐츠를 AI 플랫폼 학습용으로 제공하는 라이선스 계약을 맺음. 이는 타임스가 AI 저작권 침해로 OpenAI 등을 고소한 지 약 2년 만임.
콘텐츠 활용: 아마존은 뉴스 기사, NYT 쿠킹, 디 애슬레틱 등 타임스의 다양한 콘텐츠를 AI 플랫폼에 활용하고, 알렉사 소프트웨어에도 적용할 예정임.
의미와 파급: 이번 계약은 아마존의 첫 AI 라이선스 협약이자, 뉴욕타임스가 생성형 AI 관련 라이선스 계약을 맺은 첫 사례로 향후 언론사와 AI 기업 간의 관계에 영향을 줄 것으로 보임.
이번주 AI 논문 📝
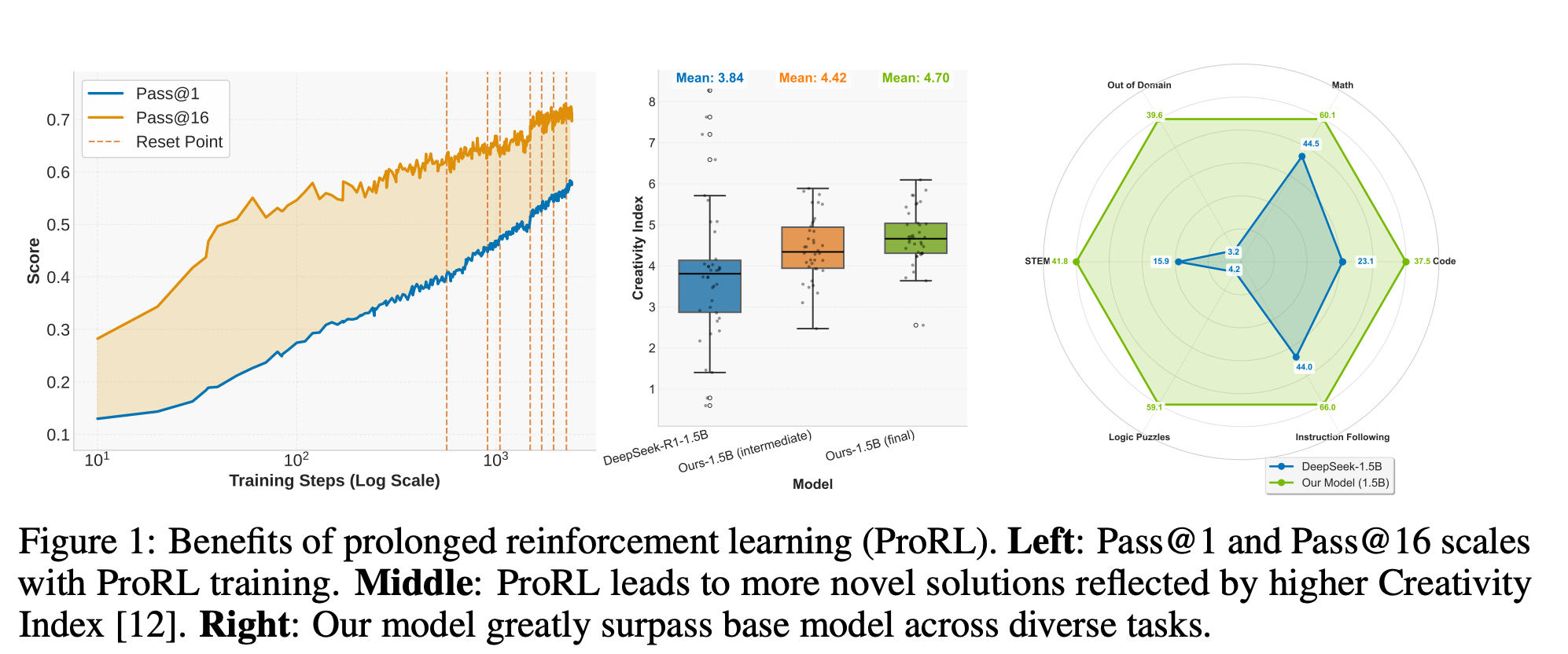
강화 학습의 역할: 대규모 언어 모델(LLM) 추론 능력 향상에 강화 학습(RL)이 유망하다는 평가가 있었지만, RL이 과연 모델의 추론 능력을 실제로 확장하는지에 대한 논란이 있었음.
ProRL 방법론 제시: 연구팀은 KL 발산 제어, 참조 정책 재설정, 다양한 작업 셋을 포함하는 ProRL(Prolonged Reinforcement Learning)이라는 새로운 훈련 방법론을 제안함.
추론 능력 확장 입증: ProRL 훈련을 통해 RL 학습 모델이 기존 모델로는 불가능했던 새로운 추론 전략을 발굴하고, 광범위한 평가에서 더 나은 성능을 보임을 입증함.

Paper2Poster: 과학 논문 기반 포스터 자동 생성 연구
포스터 생성의 도전: 과학 논문으로 학술 포스터를 만드는 것은 중요한 소통 방식이나, 긴 내용을 한 장에 시각적으로 잘 요약해야 하는 어려움이 있음.
새로운 평가 시스템 및 모델: 연구팀은 이 문제를 해결하고자 논문과 저자 제작 포스터를 기반으로 한 최초의 평가 기준과, 시각 정보를 활용하는 다중 에이전트 파이프라인 ‘Paper2Poster'를 제안함.
AI 성능과 한계: GPT-4o 같은 최신 AI도 시각적으로는 좋지만 내용 전달에 약점 보임. 반면, 연구팀의 오픈소스 모델은 더 효율적이고 성능도 우수하여, 미래 자동 포스터 모델의 발전 방향을 제시함.

긴 추론의 함정: 대규모 언어 모델(LLM)이 복잡한 추론을 위해 긴 '생각' 과정을 거치는 방식은 계산 비용과 시간이 많이 듦. 연구 결과, 오히려 짧은 추론 과정이 더 정확한 답을 내놓을 확률이 높았음.
새로운 추론 방식 'Short-m@k' 제안: 연구팀은 동시에 여러 추론을 실행하고 짧은 과정이 완료되면 멈추는 'Short-m@k'라는 새로운 추론 방법을 제안함. 이 방식은 기존 방식보다 최대 40% 적은 연산량으로 유사하거나 더 나은 성능을 보였음.
훈련 방식의 변화: 짧은 추론 과정을 이용해 LLM을 미세 조정(파인튜닝)하면 성능이 더 좋아진다는 점을 발견했음. 이는 LLM 추론에서 '오래 생각하는 것'이 항상 좋은 결과로 이어지는 것은 아니라는 중요한 시사점을 줌.
이번주 AI 프로덕트 🎁
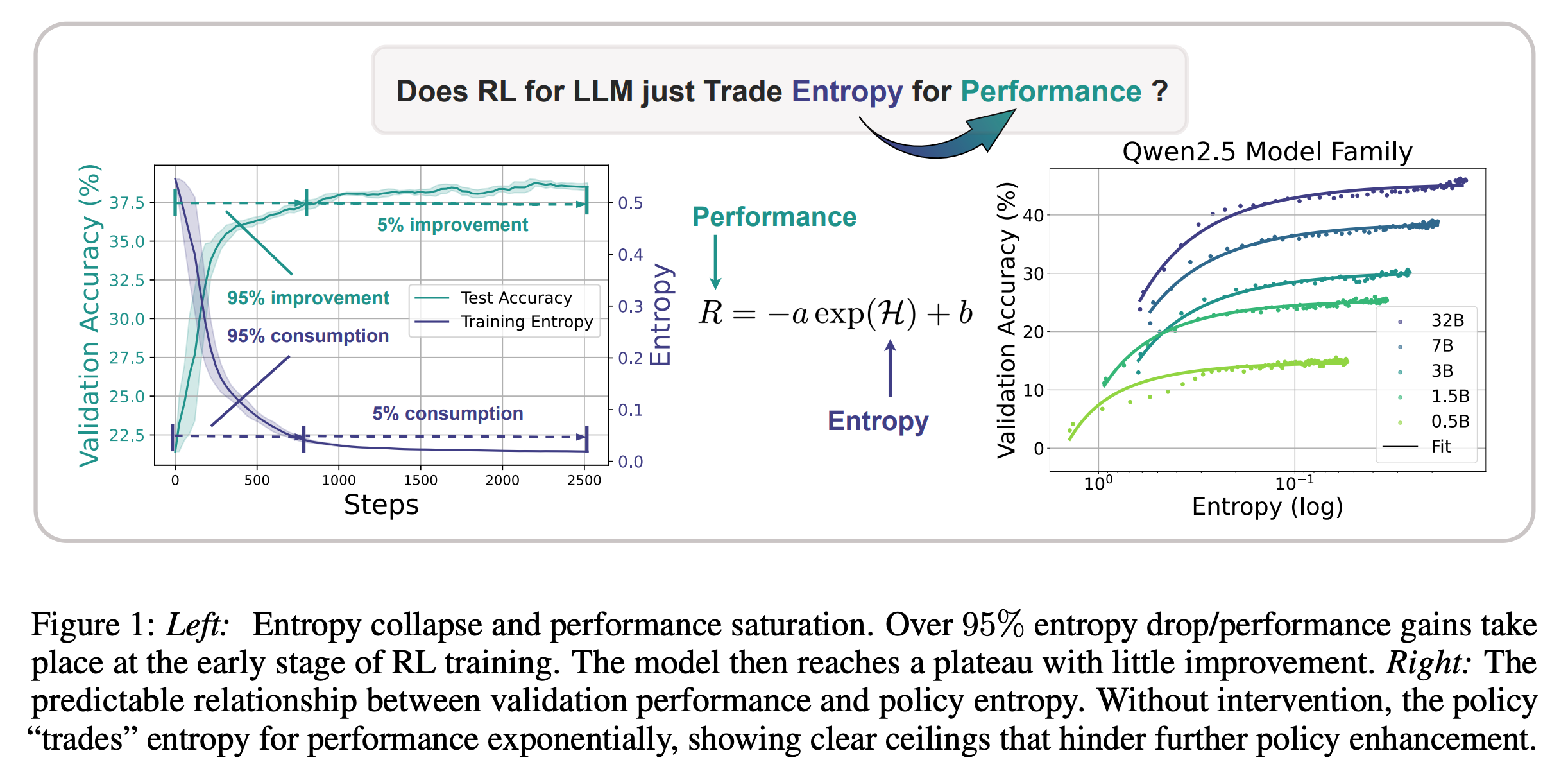
인공지능의 고민: 인공지능(AI)이 더 똑똑해지려면 계속 새로운 시도를 해야 하는데, 어느 순간부터 하던 방식만 고집하는 '탐험 정신 잃기' 현상이 나타남.
숨겨진 규칙 발견: 연구팀이 분석해보니, AI의 탐험 정신과 똑똑함 사이에 숨겨진 규칙이 있었음. 탐험 정신을 너무 일찍 잃으면 AI도 더 이상 발전하기 어렵다는 걸 알아낸 거임.
새로운 해결책 제시: 그래서 AI가 탐험 정신을 계속 유지하도록 돕는 간단하지만 효과적인 두 가지 방법(Clip-Cov, KL-Cov)을 제안했음. 이 덕분에 AI가 더 다양한 시도를 하고 더 좋은 성능을 낼 수 있게 됨.
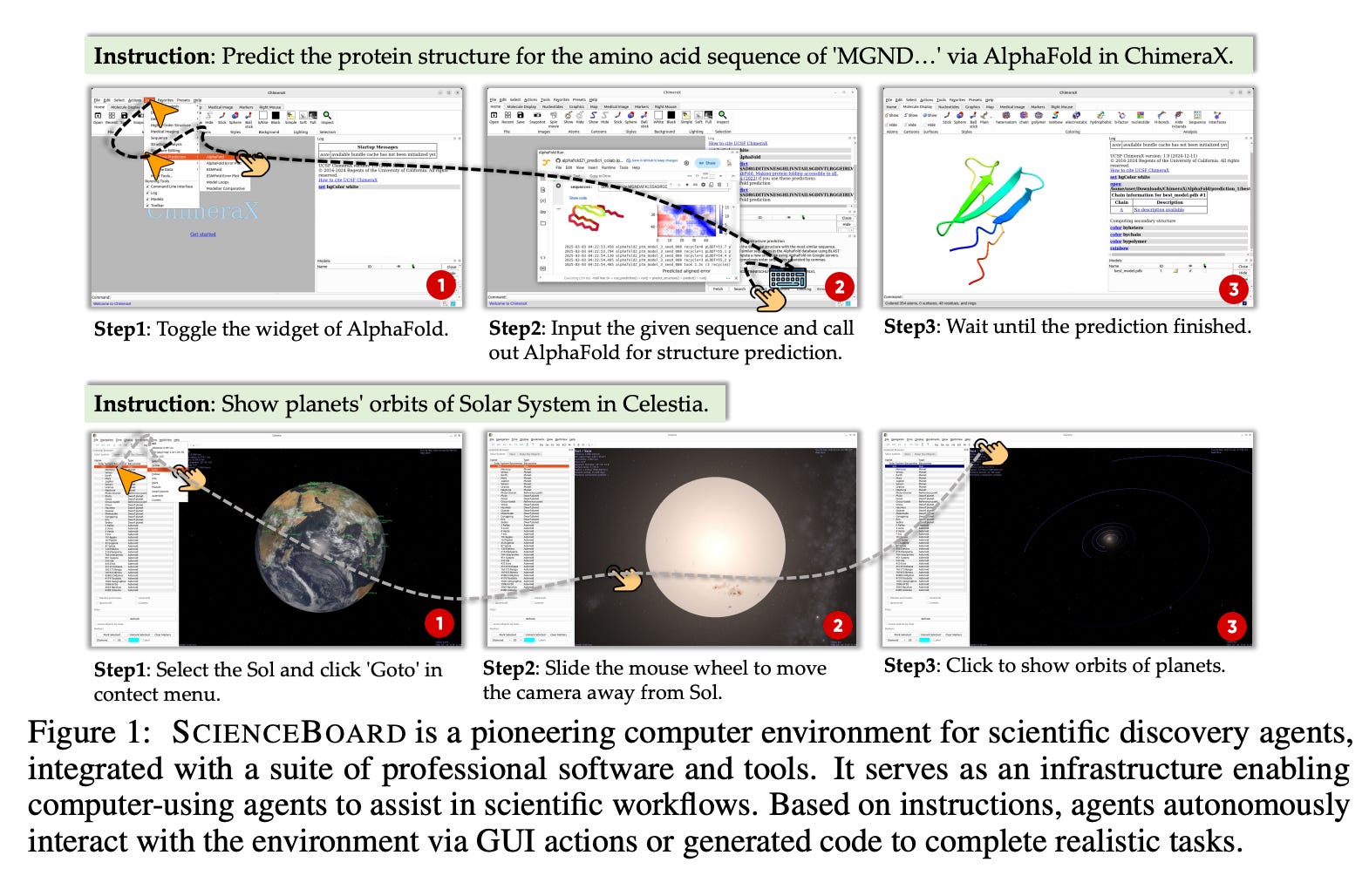
ScienceBoard: 과학적 워크플로우 내 다중모드 자율 에이전트 평가
AI 에이전트 잠재력: 대규모 언어 모델(LLM) 기반 에이전트들이 운영체제와 상호작용하며 과학 연구 문제 해결 및 일상 업무 자동화에 기여할 가능성을 보여주고 있음.
새로운 평가 환경 구축: 연구팀은 실제 과학 워크플로우를 반영한 다중 도메인 환경과 169개 고품질 실제 연구 과제로 구성된 'ScienceBoard'를 제안함. 이는 복잡한 연구 작업 가속화를 목표로 함.
현존 에이전트 한계점: GPT-4o 같은 최신 에이전트들의 평가 결과, 전체 성공률이 15%에 불과해 복잡한 과학 워크플로우에서 안정적인 지원에는 아직 미흡함을 확인. 이는 향후 에이전트 설계 개선에 중요한 시사점을 제공함.







Share this post