


이번주 AI 뉴스 📰
스튜디오 지브리 등 日 단체, OpenAI에 “저작물 무단 학습 중단” 요구
저작권 침해 : 스튜디오 지브리가 포함된 일본 단체(CODA)가 OpenAI에 저작권물 무단 학습 중단을 요구하는 서한을 보냄.
AI 무단 사용 : ChatGPT의 이미지 생성기나 Sora 등이 지브리 스타일을 무단 복제해 인기를 끈 것이 배경이 됨.
법적 쟁점 : CODA는 일본 저작권법상 명백한 위반이라 주장하며, 미야자키 하야오 감독 역시 AI에 “혐오감”을 표한 바 있음.

“칩 쌓여도 전력 없다”… MS·OpenAI, AI 전력난 ‘고심’
전력난 직면 : 나델라는 칩(GPU) 공급이 아닌 전력과 데이터센터 구축 속도가 문제이며, 칩이 있어도 꽂을 곳이 없다고 밝힘.
에너지 불확실성 : 알트먼은 저렴한 신에너지(핵융합 등)가 갑자기 등장하면 기존 고비용 전력 계약이 큰 손해가 될 것을 우려함.
수요 폭증 예상 : 알트먼은 AI 비용이 100배 저렴해지면 사용량은 100배 이상 늘어날 것(제본스의 역설)이라 예측함.

OpenAI, ‘알트먼 축출’ 직후 앤트로픽과 합병 논의?
수츠케버 증언 : 2023년 11월 알트먼 해고 직후, OpenAI가 앤트로픽과 합병을 논의한 사실이 법원 문서를 통해 밝혀짐.
이사회 반응 : 앤트로픽이 리더십을 맡는 방안에 수츠케버는 반대했으나, 헬렌 토너 등 이사회 다수는 이를 지지함.
협상 무산 : 앤트로픽 측이 ‘실무적 장애물’을 제기함에 따라, 해당 합병 논의는 단기간에 무산됨.
이번주 AI 논문 📝
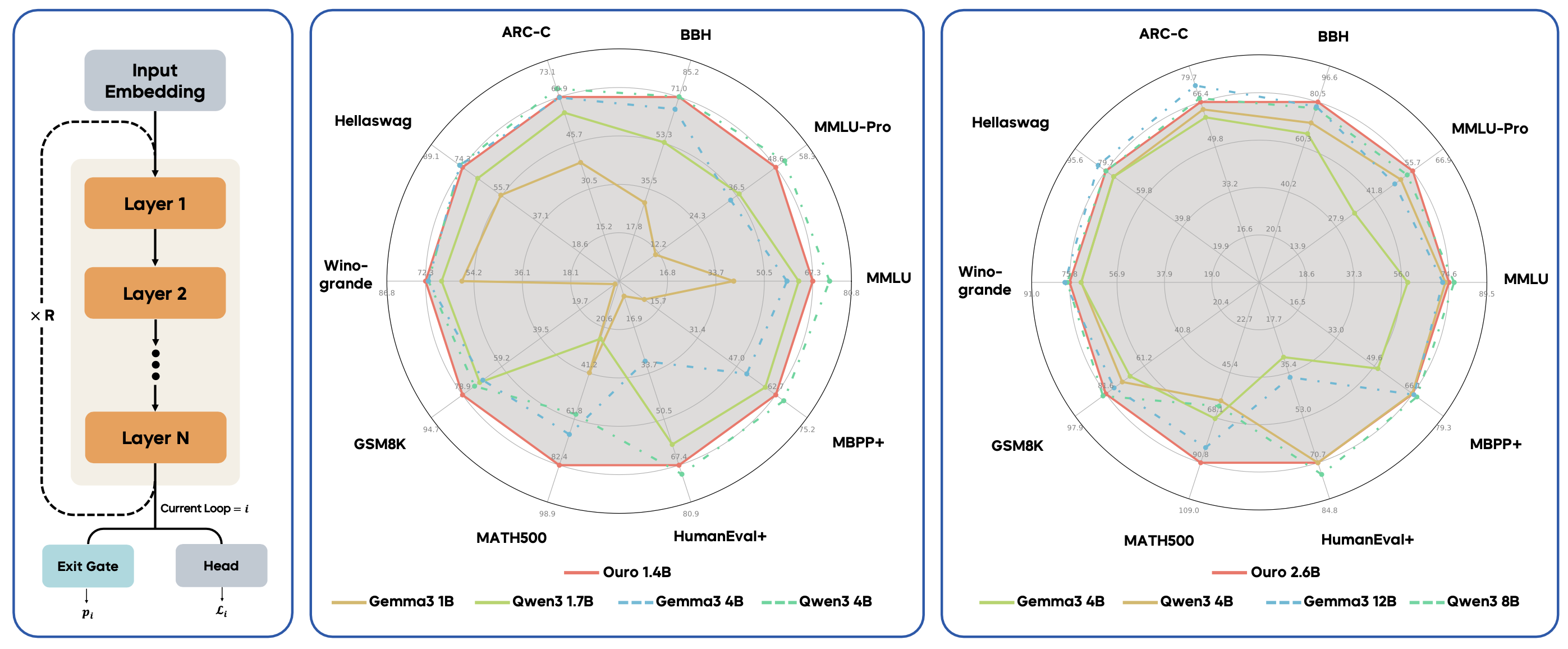
기존 한계: 현재 LLM은 훈련이 끝난 후 ‘생각의 연쇄(CoT)’라는 텍스트 생성 방식으로 추론을 학습해 비효율적이었음.
Ouro 제안: ‘Ouro(LoopLM)’는 훈련 단계부터 겉으로 글을 쓰는 대신 ‘뇌 속(잠재 공간)’에서 답을 찾을 때까지 반복 계산하며 추론 능력을 내재화함.
핵심 성과: 그 결과, 지식의 양이 아닌 ‘지식 활용 능력’이 뛰어나, 14억/26억 파라미터의 Ouro가 최대 120억 파라미터 모델 성능에 도달함.

Video-Thinker: 강화학습으로 “비디오로 생각하기” 구현
영상 추론의 한계: ‘이미지로 생각하기’ 기술은 AI 추론에 성공을 거뒀으나, 이 동적 추론 방식을 비디오 영역까지 확장할 필요가 생김.
AI의 내재된 능력 활용: ‘Video-Thinker’는 AI가 스스로 영상 속 중요 시점을 찾고(grounding) 설명(captioning)하는 내재된 능력을 추론 과정에 활용하도록 함.
훈련 및 성능: 전용 데이터셋(Video-Thinker-10K)으로 SFT(형식 학습)와 강화학습(GRPO)을 거쳐, 외부 도구 없이도 7B 모델 중 최고 성능을 달성함.
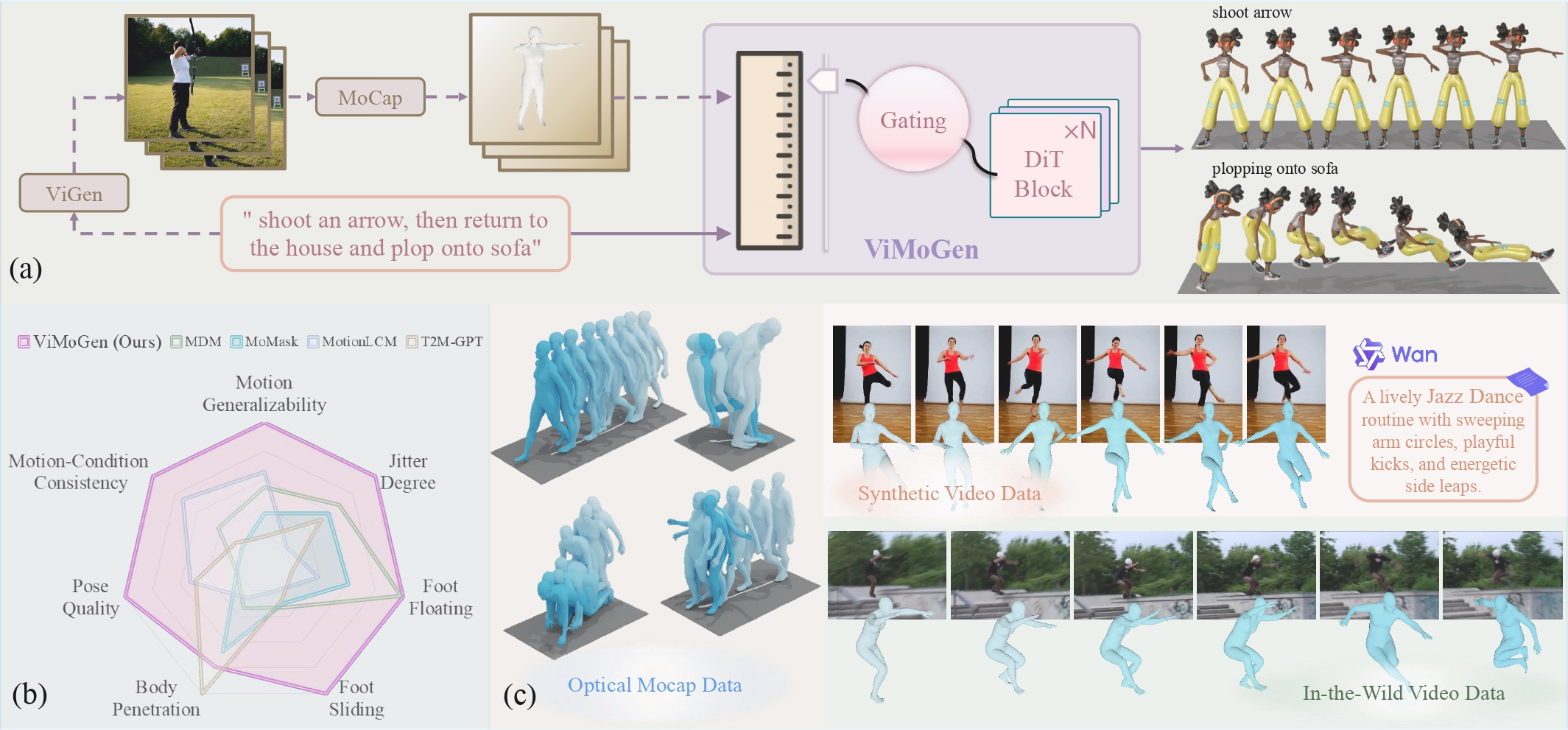
일반화 가능한 모션 생성을 위한 탐구: 데이터, 모델, 그리고 평가
모션 생성의 난제: 3D 모션 생성(MoGen)은 학습 데이터에 없는 새로운 동작을 만들어내는 일반화 능력이 부족했음.
비디오에서 배우기: 일반화가 뛰어난 비디오 생성(ViGen)의 지식을 MoGen으로 효과적으로 옮겨오는 포괄적인 프레임워크를 제안함.
3가지 변화: 이를 위해 고품질 MoCap과 ViGen 데이터를 통합한 새 데이터셋(ViMoGen-228K), 두 지식을 융합한 새 모델(ViMoGen), 일반화 성능을 정밀하게 측정하는 새 벤치마크(MBench)를 모두 개발함.
이번주 AI 프로덕트 🎁
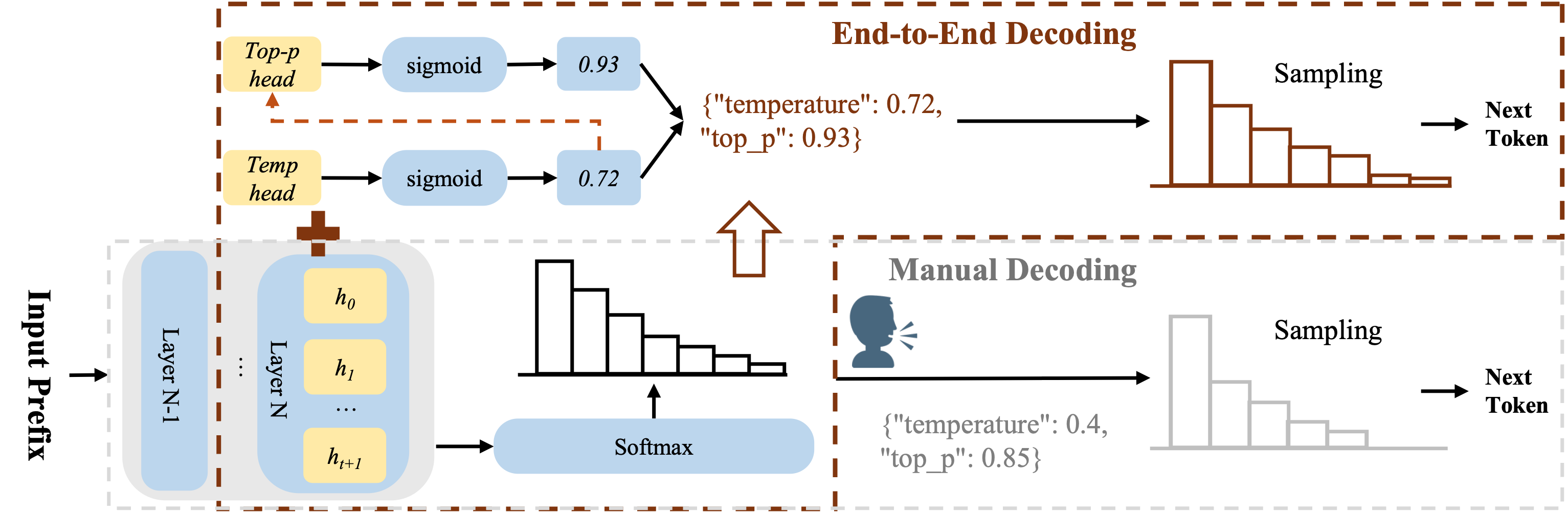
수동 디코딩의 종말: 진정한 엔드투엔드 언어 모델을 향해
기존 디코딩 한계: LLM은 온도(temperature)나 top-p 같은 하이퍼파라미터를 수동으로 조정해야 해, 진정한 ‘End-to-End’가 아니었음.
AutoDeco 제안: LLM이 매 토큰 생성 시 최적의 온도와 top-p 값을 스스로 예측하는 가벼운 헤드(head)를 추가한 ‘AutoDeco’ 아키텍처를 제안함.
성능 및 발견: AutoDeco는 수동 조정을 뛰어넘는 성능을 보였으며, “창의적으로 생성해” 같은 자연어 명령을 이해해 스스로 디코딩 전략을 조절하는 능력도 발견함.

Emu3.5: 네이티브 멀티모달 모델은 세계를 학습한다
Emu3.5 모델 소개: 10조 개 이상의 비디오 프레임/자막 데이터로 학습, 텍스트와 이미지가 혼합된 ‘다음 토큰’을 예측하는 네이티브 멀티모달 월드 모델을 제안함.
주요 능력: 텍스트와 이미지가 섞인 긴 시퀀스 생성, ‘Any-to-Image’ 편집, 텍스트가 풍부한 이미지 생성 및 로봇 조작(embodied manipulation) 등 복잡한 작업에서 강점을 보임.
추론 효율성 확보: ‘DiDA’ 기술로 기존 토큰 단위 이미지 생성을 병렬 예측으로 변환, 성능 저하 없이 추론 속도를 약 20배가량 가속함.







