


이번주 AI 뉴스 📰
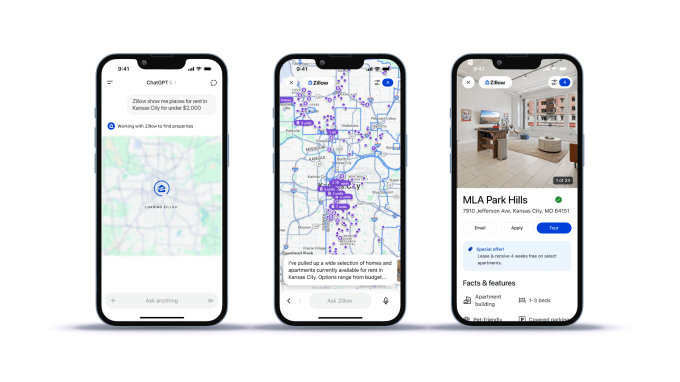
OpenAI, ChatGPT에 외부 앱 탑재... AI 생태계 확장 본격화
외부 앱 탑재 : OpenAI가 챗GPT 내에서 스포티파이, 부킹닷컴 등 외부 앱을 직접 불러와 사용하는 기능을 출시했음.
대화형 사용법 : 사용자가 대화 중 직접 앱을 호출하거나 챗GPT가 맥락에 맞춰 앱을 추천, 채팅창에서 바로 상호작용이 가능함.
생태계 확장 : 이번 출시로 챗GPT 중심의 앱 생태계를 본격 구축하려는 시도지만, 데이터 프라이버시 등의 과제는 남아있음.

OpenAI, AI 에이전트 개발 툴킷 ‘AgentKit’ 전격 공개
개발 툴킷 공개 : OpenAI가 AI 에이전트 개발부터 배포, 최적화까지 전 과정을 지원하는 종합 툴킷 ‘AgentKit’을 발표했음.
핵심 기능 소개 : 시각적 설계 도구인 ‘에이전트 빌더’와 채팅 UI ‘챗킷’, 성능 평가 도구, 외부 시스템 연결 기능 등을 제공함.
개발 장벽 완화 : 복잡한 AI 에이전트 개발 과정을 단순화하여 개발자들의 참여를 유도하고 AI 생태계 경쟁에서 앞서나가기 위함임.

OpenAI, Dev Day에 강력한 새 API 대거 공개
GPT-5 Pro API 공개 : 금융, 법률 등 고도의 정확성과 추론 능력이 필요한 전문 분야를 위한 최신 언어 모델 ‘GPT-5 Pro’를 API로 출시함.
음성·영상 모델 : 기존보다 70% 저렴한 실시간 음성 모델 gpt-realtime mini와 사실적인 영상 생성 AI ‘Sora 2’를 API에 새롭게 추가했음.
개발자 생태계 : 강력한 신규 모델들을 API로 제공해 더 많은 개발자를 유치하고, 자사 AI 플랫폼의 경쟁력을 강화하려는 전략임.
이번주 AI 논문 📝
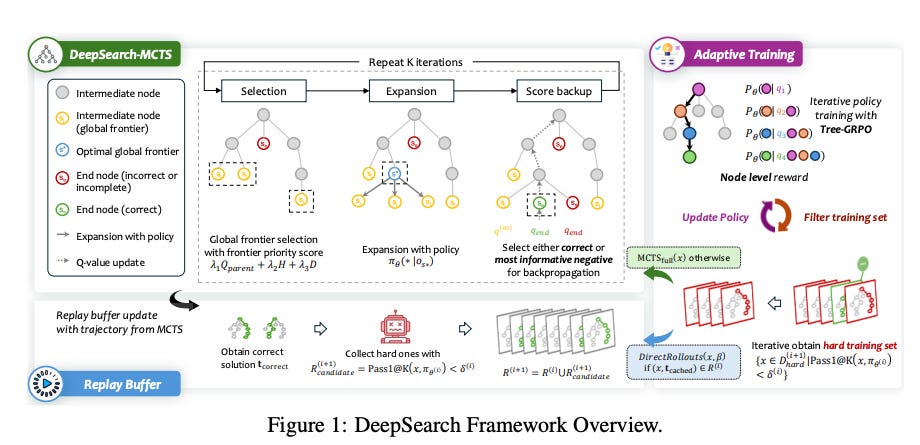
DeepSearch: MCTS를 활용한 RLVR 훈련 병목 현상 극복
RLVR 한계 극복 : 기존 강화 학습(RLVR)의 탐색 부족으로 인한 성능 정체 문제를 해결하기 위해, 몬테카를로 트리 탐색(MCTS)을 훈련 과정에 직접 통합함.
체계적 탐색 도입 : 추론이 아닌 훈련 중에 체계적인 탐색을 수행하여, 추론 과정의 각 단계에 세밀한 보상을 부여하고 솔루션 공간을 효과적으로 탐색함.
압도적인 훈련 효율 : 기존 방식 대비 5.7배 적은 GPU 자원으로 1.5B 모델 수학 추론 벤치마크에서 새로운 최고 성능(SOTA)을 달성함.

LongCodeZip: 코드 언어 모델을 위한 긴 컨텍스트 압축 프레임워크
코드 컨텍스트 압축 : 코드 LLM의 긴 컨텍스트로 인한 비용 및 지연 문제를 해결하기 위해 설계된 압축 프레임워크 ‘LongCodeZip’을 제안함.
2단계 압축 전략 : 관련 함수를 선별하는 거친 압축과 함수 내 중요 블록을 최적으로 선택하는 세밀한 압축을 순차적으로 적용함.
성능 저하 없는 압축 : 다양한 코드 과제에서 성능 저하 없이 최대 5.6배의 압축률을 달성하며 LLM의 효율성과 확장성을 크게 향상시킴.
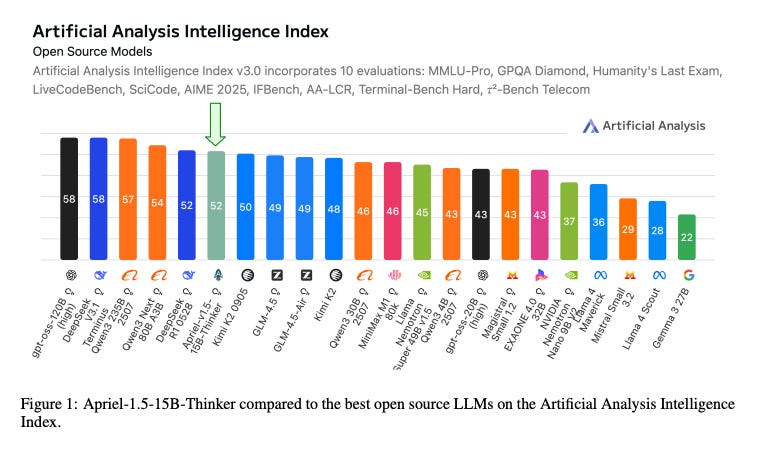
Apriel-1.5-15B-Thinker: 중간 훈련(Mid-training)만으로 충분하다
소형 고성능 모델 : 규모가 아닌 정교한 훈련 설계를 통해 최상위 성능을 달성한 150억 파라미터 규모의 오픈소스 멀티모달 추론 모델을 제시함.
3단계 훈련법 : 깊이 확장, 단계적 지속 사전 훈련, 고품질 데이터 기반의 지도 미세조정 등 3단계 방법론을 적용하여 모델을 개발함.
효율성 입증 : 적은 컴퓨팅 자원으로도 주요 모델들과 대등한 성능을 보이며, 제한된 인프라에서의 활용 가능성을 입증함.
이번주 AI 프로덕트 🎁
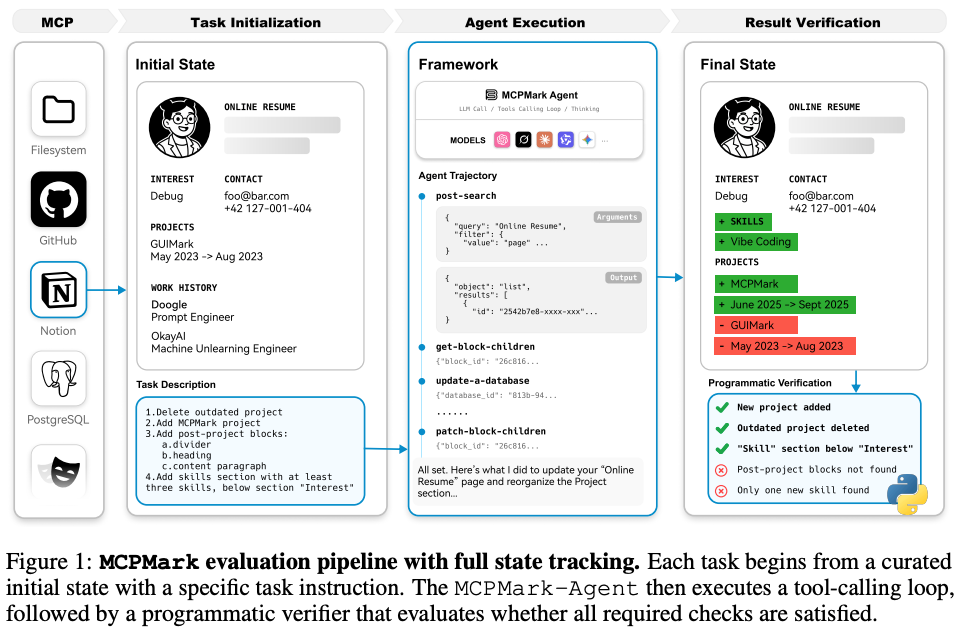
MCPMark: 현실적이고 포괄적인 MCP 활용도 평가를 위한 스트레스 테스트 벤치마크
현실적 벤치마크 : 실제 워크플로우의 복잡성을 반영한 127개의 고품질 태스크로 구성된 신규 벤치마크 ‘MCPMark’를 제안함.
LLM 성능 한계 : 최첨단 LLM들도 평균 16.2회의 상호작용이 필요한 복잡한 태스크에서 낮은 성공률을 기록하며 한계를 드러냄.
벤치마크의 의의 : 다양한 CRUD (Create, Read, Update, Delete) 작업을 요구하여, LLM 에이전트의 안정성 및 계획 능력에 대한 심층적인 스트레스 테스트를 제공함.

Vision-Zero: 전략적 게임을 통한 확장 가능한 VLM 자가 개선 프레임워크
게임 기반 자가 학습 : 기존의 막대한 비용이 드는 수동 데이터 구축 방식에서 벗어나, AI 모델이 ‘스파이 찾기’와 유사한 시각 게임을 통해 스스로 학습 데이터를 생성하고 전략적 추론 능력을 향상시키는 프레임워크를 제안함.
지속적인 성능 향상 : 자가 학습만으로 발생할 수 있는 성능 정체기를 극복하기 위해, ‘반복적 자가 플레이 정책 최적화(Iterative-SPO)’라는 새로운 훈련 알고리즘을 도입하여 장기적이고 지속적인 성능 개선을 달성함.
비용 효율 및 성능 : 사람의 개입 없이 생성된 데이터만으로도 기존의 고비용 데이터 기반 모델들을 뛰어넘는 최첨단 성능을 추론, 차트 질의응답 등 다양한 분야에서 보여줌.







