


이번주 AI 뉴스 📰

ChatGPT 이후 최대 기대작, OpenAI ‘Sora’ 돌연 서비스 종료
Sora 중단 : OpenAI가 막대한 컴퓨팅 자원 소모와 수익성 부족을 이유로 AI 영상 생성 모델 Sora의 서비스를 갑작스럽게 중단함.
기업용 집중 : 경쟁사 Anthropic 등에 뒤처진 상황을 극복하고자, 한정된 자원을 업무용 AI 에이전트 개발에 집중하기로 결정함.
투자 백지화 : Sora를 도입하려던 Disney의 10억 달러 규모 투자 및 파트너십 계획이 이번 서비스 종료 결정으로 전면 무산됨.

음악계에 스며든 AI: 톱 프로듀서들이 ‘쉬쉬’하며 사용하는 이유
조용한 확산 : 음악계 톱 프로듀서와 작곡가들 사이에서 Suno 등 AI 도구 사용이 늘고 있으나, 사회적 비난을 우려해 이를 숨기는 분위기가 만연함.
양날의 검 : 음원 분리 및 데모 제작 등 작업 효율을 극대화하지만, 미해결된 저작권 문제와 신진 음악인들의 일자리를 위협한다는 우려가 커지고 있음.
아날로그 회귀 : 흥미롭게도 젊은 뮤지션들을 중심으로 AI 특유의 인위적인 소리에 거부감을 느끼고 인간의 결함이 담긴 자연스러운 음악을 선호하는 현상이 나타남.

Anthropic 보안 사고… 미출시 AI 모델 및 내부 데이터 유출
내부 자료 유출 : Anthropic의 콘텐츠 관리 시스템(CMS) 설정 오류로 약 3,000개의 미공개 내부 자산이 대중에게 노출됨.
기밀 정보 포함 : 유출된 데이터에는 성능이 대폭 향상된 차세대 AI 모델의 세부 정보와 비공개 CEO 행사 일정 등 민감한 정보가 포함되어 있었음.
단순 인적 오류 : Fortune의 통보 직후 데이터 접근을 차단했으며, 이번 유출은 Claude 등 AI 결함이 아닌 직원의 단순 설정 실수라고 해명함.
이번주 AI 논문 📝
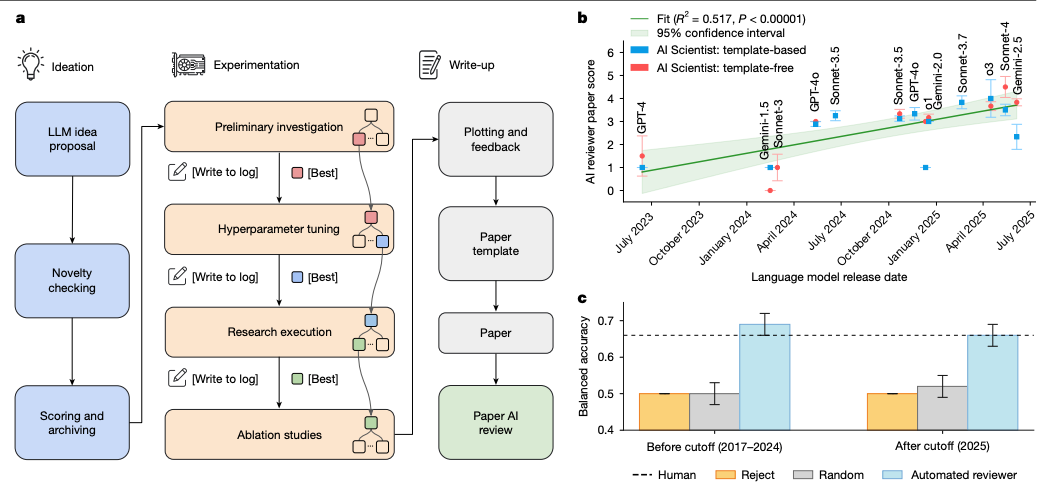
AI 연구의 전 과정을 자율적으로 수행하는 통합 프레임워크
연구 환경의 한계점 : 과학적 발견의 개별 단계 자동화를 넘어 연구 전 과정의 자율적 통합이 부재한 상황임.
전주기 에이전트 구축 : 현대 파운데이션 모델을 기반으로 가설 설정부터 실험 수행 및 논문 작성까지 전 공정을 수행하는 지능형 에이전트를 구현함.
자율적 연구 성과 입증 : 생성된 결과물이 실제 학술대회 심사 기준을 통과하며 인공지능 주도의 독자적인 과학적 기여 가능성을 확인함.
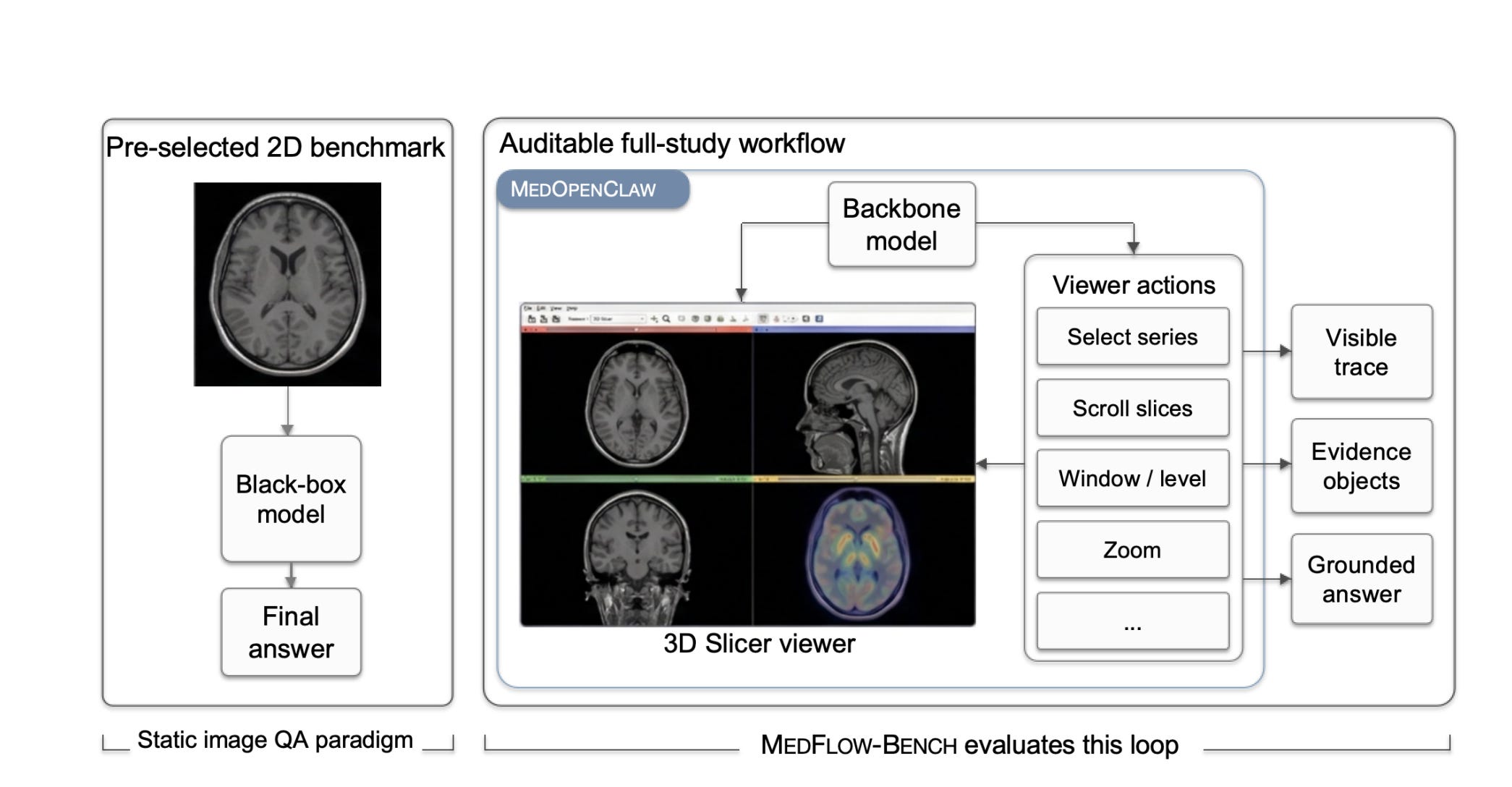
MedOpenClaw: 능동적 임상 의사결정을 지원하는 3D 의료 영상 분석 에이전트
실제 진단의 한계 : 미리 선별된 2D 이미지만으로 학습된 기존 AI 모델과 실제 3D 입체 영상을 탐색해야 하는 의료 현장 사이의 괴리를 지목함
지능형 탐색 도입 : 의료용 뷰어를 직접 조작하며 3D 볼륨 데이터를 스스로 탐색하고 증거를 수집할 수 있는 동적 실행 환경을 제안함
정밀 제어의 과제 : 최신 AI가 영상 흐름은 잘 이해하나 전문 도구 사용 시 필요한 세밀한 위치 지정 능력에는 한계가 있음을 밝혀냄
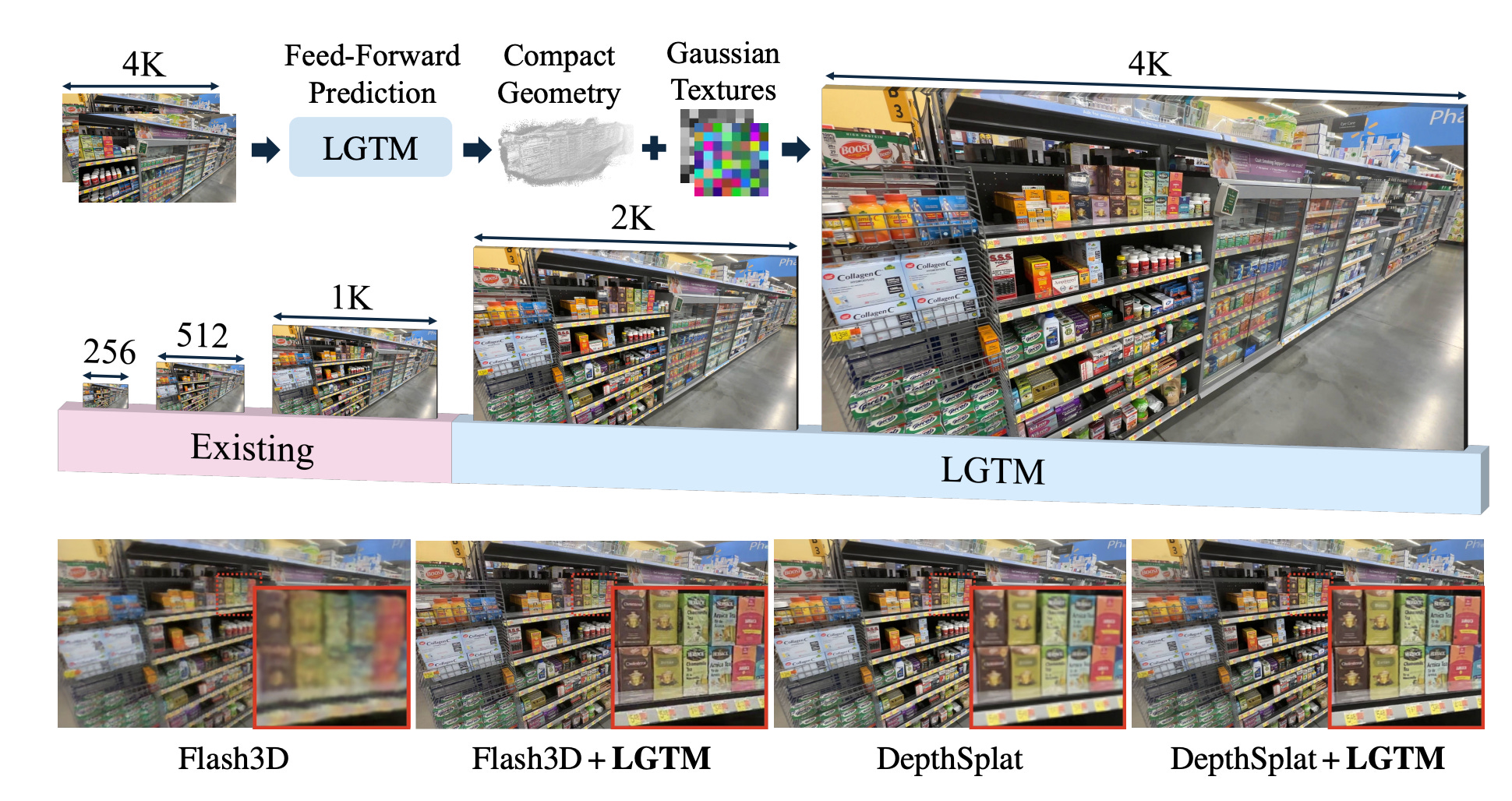
질감 중심의 구조 분리 기반 4K 고해상도 3D 가우시안 스플래팅 기술
확장의 한계 : 해상도 증가에 따른 연산 자원 소모의 급격한 증가로 인해 4K급 고해상도 3D 복원 구현이 어려웠던 제약을 지목함
구조적 변화 : 형상 정보와 세부 질감을 독립적으로 예측하여 적은 수의 데이터만으로도 정교한 외형 묘사가 가능한 이중 네트워크를 제안함
효율적 구현 : 별도의 추가 최적화 없이 4K급 고화질 영상을 생성하며 기존 대비 압도적인 메모리 효율과 처리 속도를 입증함
이번주 AI 프로덕트 🎁

놓치는 순간 : 기존 영상 AI는 사람이 화면 밖으로 잠깐 사라졌다 돌아오면 어디에 있었는지, 어떻게 움직이고 있었는지를 자주 놓쳐서 멈추거나 이상하게 바뀌는 문제가 있었음
새로운 기억법 : 이 논문은 배경은 안정적으로 기억하고 움직이는 대상은 따로 추적하는 방식의 하이브리드 메모리를 제안했고, 이를 검증하려고 전용 영상 데이터셋 HM-World와 HyDRA 구조를 만들었음
더 자연스러운 복귀 : 그 결과 화면 밖에 있던 사람이 다시 등장해도 같은 인물처럼 자연스럽게 이어서 움직이게 만들었고, 기존 방법들보다 영상의 자연스러움과 일관성이 더 좋아졌음
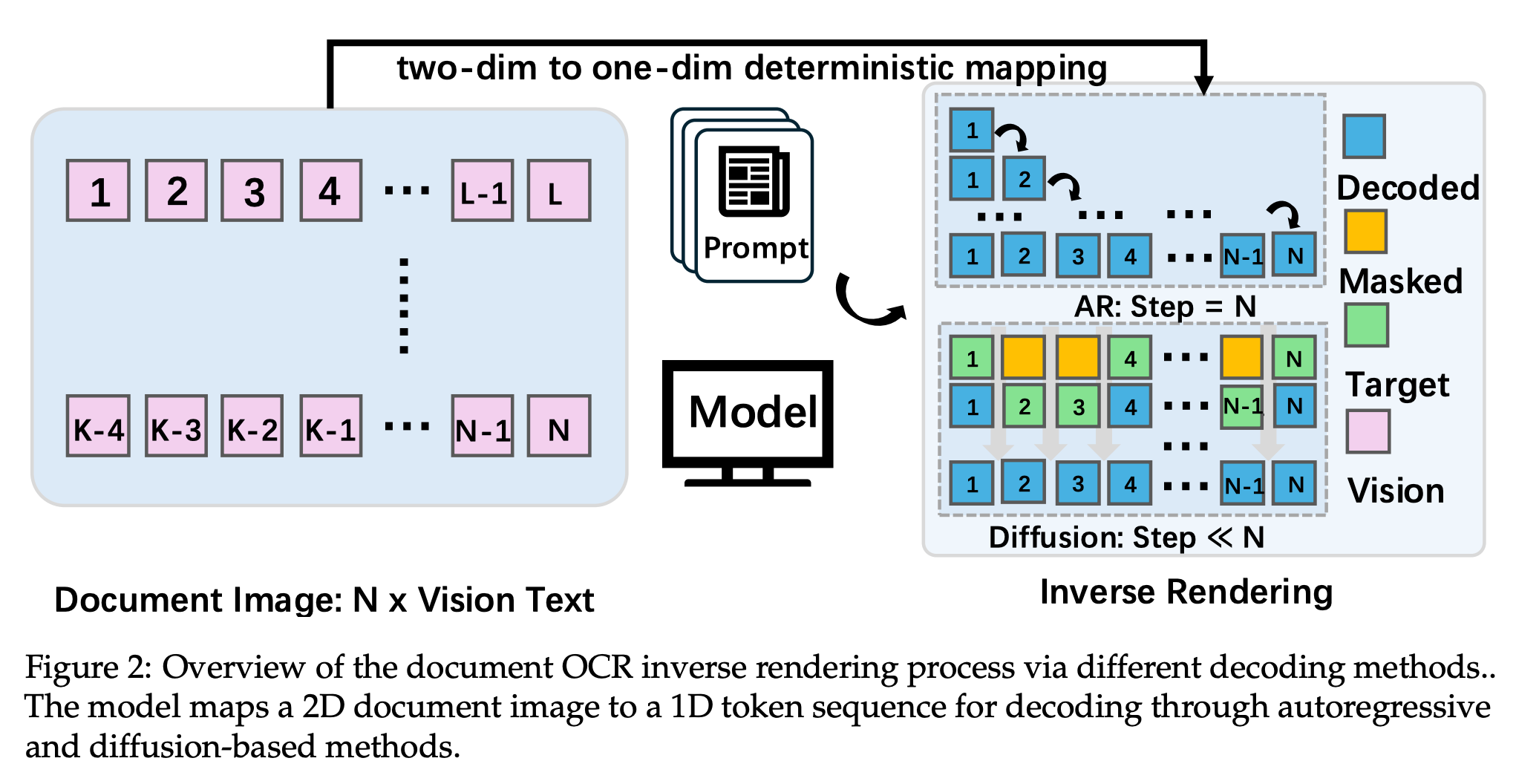
디퓨전 디코딩을 활용한 역렌더링 기반 차세대 문서 인식 프레임워크
기존 방식의 한계 : 글자를 하나씩 순서대로 읽는 기존 방식의 느린 속도와 긴 문장에서 발생하는 오답 누적 문제를 핵심 걸림돌로 규정함
병렬적 역렌더링 : 문서를 한 번에 그려내는 디퓨전 기법과 인공지능이 헷갈려 하는 부분을 집중 학습시키는 전략을 도입함
성능 및 효율성 : 읽기 속도를 3.2배 높이면서도 문맥에만 의존하지 않고 이미지 속 글자 그대로를 정확하게 읽어내는 능력을 증명함







